tf-recsys-master
所属分类:其他
开发工具:Python
文件大小:13KB
下载次数:8
上传日期:2019-04-30 20:06:26
上 传 者:
sure668
说明: 数据挖掘,专用于电影的推荐,主要是对推荐系统算法的研究
(Data mining, dedicated to film recommendations, mainly research on recommendation system algorithms)
文件列表:
LICENSE (1064, 2018-01-13)
setup.cfg (40, 2018-01-13)
setup.py (904, 2018-01-13)
tfcf (0, 2018-01-13)
tfcf\__init__.py (0, 2018-01-13)
tfcf\config.py (433, 2018-01-13)
tfcf\datasets (0, 2018-01-13)
tfcf\datasets\__init__.py (0, 2018-01-13)
tfcf\datasets\ml100k.py (430, 2018-01-13)
tfcf\datasets\ml1m.py (446, 2018-01-13)
tfcf\metrics.py (522, 2018-01-13)
tfcf\models (0, 2018-01-13)
tfcf\models\__init__.py (0, 2018-01-13)
tfcf\models\model_base.py (2048, 2018-01-13)
tfcf\models\svd.py (7655, 2018-01-13)
tfcf\models\svdpp.py (6676, 2018-01-13)
tfcf\utils (0, 2018-01-13)
tfcf\utils\__init__.py (0, 2018-01-13)
tfcf\utils\data_utils.py (1712, 2018-01-13)
# tf-recsys
## Overview
**tf-recsys** contains collaborative filtering (CF) model based on famous SVD and SVD++ algorithm. Both of them are implemented by [Tensorflow][Tensorflow] in order to utilize GPU acceleration.
## Installation
```
pip install tfcf
```
Note that if you want to use GPU, please pre-install [Tensorflow][Tensorflow] with GPU version, that is, run
```
pip install tensorflow-gpu
```
or follow the instructions at [Installing Tensorflow](https://www.tensorflow.org/install/).
## Algorithms
### SVD
SVD algorithm does matrix factorization via the following formula:

LHS is the prediction rating. The objective function is summation of the L2 loss between prediction and real rating and the regularization terms. For parameter updating, the gradient descent is used to minimize objective function.
### SVD++
Similar to SVD, the original SVD++ algorithm incorporate *implicit feedback* of users.

The 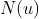 here is the set of implicit feedback of users.
In this package, we also provide *dual* option for SVD++, or incoporate the implicit feedback of items. The equation can be re-written as follows:

where 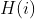 is the set of implicit feedback of items.
In our experiments, dual SVD++ outperform both original SVD++ and SVD but with slower training procedure.
## Example
```python
import numpy as np
import tensorflow as tf
from tfcf.metrics import mae
from tfcf.metrics import rmse
from tfcf.datasets import ml1m
from tfcf.config import Config
from tfcf.models.svd import SVD
from tfcf.models.svd import SVDPP
from sklearn.model_selection import train_test_split
# Note that x is a 2D numpy array,
# x[i, :] contains the user-item pair, and y[i] is the corresponding rating.
x, y = ml1m.load_data()
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=0)
config = Config()
config.num_users = np.max(x[:, 0]) + 1
config.num_items = np.max(x[:, 1]) + 1
config.min_value = np.min(y)
config.max_value = np.max(y)
with tf.Session() as sess:
# For SVD++ algorithm, if `dual` is True, then the dual term of items'
# implicit feedback will be added into the original SVD++ algorithm.
# model = SVDPP(config, sess, dual=False)
# model = SVDPP(config, sess, dual=True)
model = SVD(config, sess)
model.train(x_train, y_train, validation_data=(
x_test, y_test), epochs=20, batch_size=1024)
y_pred = model.predict(x_test)
print('rmse: {}, mae: {}'.format(rmse(y_test, y_pred), mae(y_test, y_pred)))
# Save model
model = model.save_model('model/')
# Load model
# model = model.load_model('model/')
```
## Performance
The experiments are set up on [MovieLens 100K][MovieLens100K] and [MovieLens 1M][MovieLens1M]. The results reported here are evaluated on 5-folds cross validation with random seed 0 and taken average of them. All models use default configuration. For [MovieLens 100K][MovieLens100K], the batch size is 128. As for [MovieLens 1M][MovieLens1M], a quite larger dataset, the batch size is 1024. With GPU acceleration, both SVD and SVD++ speed up significantly compared with [Surprise][Surprise], which is the implementation based on cPython. The following is the performance on GTX 1080:
### MovieLens 100K
| | RMSE | MAE | Time (sec/epoch) |
|:----------:|:-------:|:-------:|:----------------:|
| SVD | 0.91572 | 0.719*** | < 1 |
| SVD++ | 0.90484 | 0.70***2 | 4 |
| Dual SVD++ | 0.89334 | 0.70020 | 7 |
### MovieLens 1M
| | RMSE | MAE | Time (sec/epoch) |
|:----------:|:-------:|:-------:|:----------------:|
| SVD | 0.85524 | 0.66922 | 4 |
| SVD++ | 0.84846 | 0.66306 | 40 |
| Dual SVD++ | 0.83672 | 0.65256 | 50 |
Some similar experiments can be found at [MyMediaLite][MyMediaLite], [Surprise][Surprise] and [LibRec][LibRec].
## References
[Tensorflow][Tensorflow]
[MyMediaLite][MyMediaLite]
[Surprise][Surprise]
[LibRec][LibRec]
Also see my [ML2017][ML2017] repo, there is a [Keras][Keras] implementation for SVD and SVD++ in [hw6][hw6].
[MovieLens100K]: https://grouplens.org/datasets/movielens/100k/
[MovieLens1M]: https://grouplens.org/datasets/movielens/1m/
[LibRec]: https://www.librec.net/release/v1.3/example.html
[Tensorflow]: https://www.tensorflow.org/
[Keras]: https://keras.io/
[MyMediaLite]: http://www.mymedialite.net/examples/datasets.html
[Surprise]: https://github.com/NicolasHug/Surprise
[ML2017]: https://github.com/WindQAQ/ML2017
[hw6]: https://github.com/WindQAQ/ML2017/blob/master/hw6/train.py
## Contact
Issues and pull requests are welcomed. Feel free to [contact me](mailto:windqaq@gmail.com) if there's any problems.
近期下载者:
相关文件:
收藏者: