Multi-Label-Text-Classification-master
所属分类:人工智能/神经网络/深度学习
开发工具:Python
文件大小:102KB
下载次数:3
上传日期:2019-12-23 18:00:27
上 传 者:
cecilia_2019
说明: 基于深度学习的多标签文本分类 包括ann、cnn、rnn、fasttext、han模型,基于tensoflow
(multi label text classfication)
文件列表:
.travis.yml (242, 2019-04-04)
ANN (0, 2019-04-04)
ANN\test_ann.py (11638, 2019-04-04)
ANN\text_ann.py (5895, 2019-04-04)
ANN\train_ann.py (18020, 2019-04-04)
CNN (0, 2019-04-04)
CNN\test_cnn.py (11833, 2019-04-04)
CNN\text_cnn.py (7551, 2019-04-04)
CNN\train_cnn.py (18334, 2019-04-04)
CRNN (0, 2019-04-04)
CRNN\test_crnn.py (11934, 2019-04-04)
CRNN\text_crnn.py (9424, 2019-04-04)
CRNN\train_crnn.py (18519, 2019-04-04)
FastText (0, 2019-04-04)
FastText\test_fast.py (11558, 2019-04-04)
FastText\text_fast.py (5313, 2019-04-04)
FastText\train_fast.py (18102, 2019-04-04)
HAN (0, 2019-04-04)
HAN\test_han.py (11734, 2019-04-04)
HAN\text_han.py (8326, 2019-04-04)
HAN\train_han.py (18173, 2019-04-04)
LICENSE (11357, 2019-04-04)
RCNN (0, 2019-04-04)
RCNN\test_rcnn.py (11934, 2019-04-04)
RCNN\text_rcnn.py (9727, 2019-04-04)
RCNN\train_rcnn.py (18519, 2019-04-04)
RNN (0, 2019-04-04)
RNN\test_rnn.py (11734, 2019-04-04)
RNN\text_rnn.py (10908, 2019-04-04)
RNN\train_rnn.py (18173, 2019-04-04)
SANN (0, 2019-04-04)
SANN\test_sann.py (12013, 2019-04-04)
SANN\text_sann.py (12163, 2019-04-04)
SANN\train_sann.py (18600, 2019-04-04)
data (0, 2019-04-04)
data\data_sample.json (795, 2019-04-04)
requirements.txt (215, 2019-04-04)
... ...
# Deep Learning for Multi-Label Text Classification
[](https://www.python.org/downloads/) [](https://travis-ci.org/RandolphVI/Multi-Label-Text-Classification) [](https://www.codacy.com/app/chinawolfman/Multi-Label-Text-Classification?utm_source=github.com&utm_medium=referral&utm_content=RandolphVI/Multi-Label-Text-Classification&utm_campaign=Badge_Grade) [](https://www.apache.org/licenses/LICENSE-2.0) [](https://github.com/RandolphVI/Multi-Label-Text-Classification/issues)
This repository is my research project, and it is also a study of TensorFlow, Deep Learning (Fasttext, CNN, LSTM, etc.).
The main objective of the project is to solve the multi-label text classification problem based on Deep Neural Networks. Thus, the format of the data label is like [0, 1, 0, ..., 1, 1] according to the characteristics of such a problem.
## Requirements
- Python 3.6
- Tensorflow 1.1 +
- Numpy
- Gensim
## Innovation
### Data part
1. Make the data support **Chinese** and English (Which use `jieba` seems easy).
2. Can use **your own pre-trained word vectors** (Which use `gensim` seems easy).
3. Add embedding visualization based on the **tensorboard**.
### Model part
1. Add the correct **L2 loss** calculation operation.
2. Add **gradients clip** operation to prevent gradient explosion.
3. Add **learning rate decay** with exponential decay.
4. Add a new **Highway Layer** (Which is useful according to the model performance).
5. Add **Batch Normalization Layer**.
### Code part
1. Can choose to **train** the model directly or **restore** the model from the checkpoint in `train.py`.
2. Can predict the labels via **threshold** and **top-K** in `train.py` and `test.py`.
3. Can calculate the evaluation metrics --- **AUC** & **AUPRC**.
4. Add `test.py`, the **model test code**, it can show the predicted values and predicted labels of the data in Testset when creating the final prediction file.
5. Add other useful data preprocess functions in `data_helpers.py`.
6. Use `logging` for helping to record the whole info (including **parameters display**, **model training info**, etc.).
7. Provide the ability to save the best n checkpoints in `checkmate.py`, whereas the `tf.train.Saver` can only save the last n checkpoints.
## Data
See data format in `data` folder which including the data sample files.
### Text Segment
You can use `jieba` package if you are going to deal with the Chinese text data.
### Data Format
This repository can be used in other datasets (text classification) in two ways:
1. Modify your datasets into the same format of the sample.
2. Modify the data preprocess code in `data_helpers.py`.
Anyway, it should depend on what your data and task are.
### Pre-trained Word Vectors
You can pre-training your word vectors (based on your corpus) in many ways:
- Use `gensim` package to pre-train data.
- Use `glove` tools to pre-train data.
- Even can use a **fasttext** network to pre-train data.
## Network Structure
### FastText

References:
- [Bag of Tricks for Efficient Text Classification](https://arxiv.org/pdf/1607.01759.pdf)
---
### TextANN
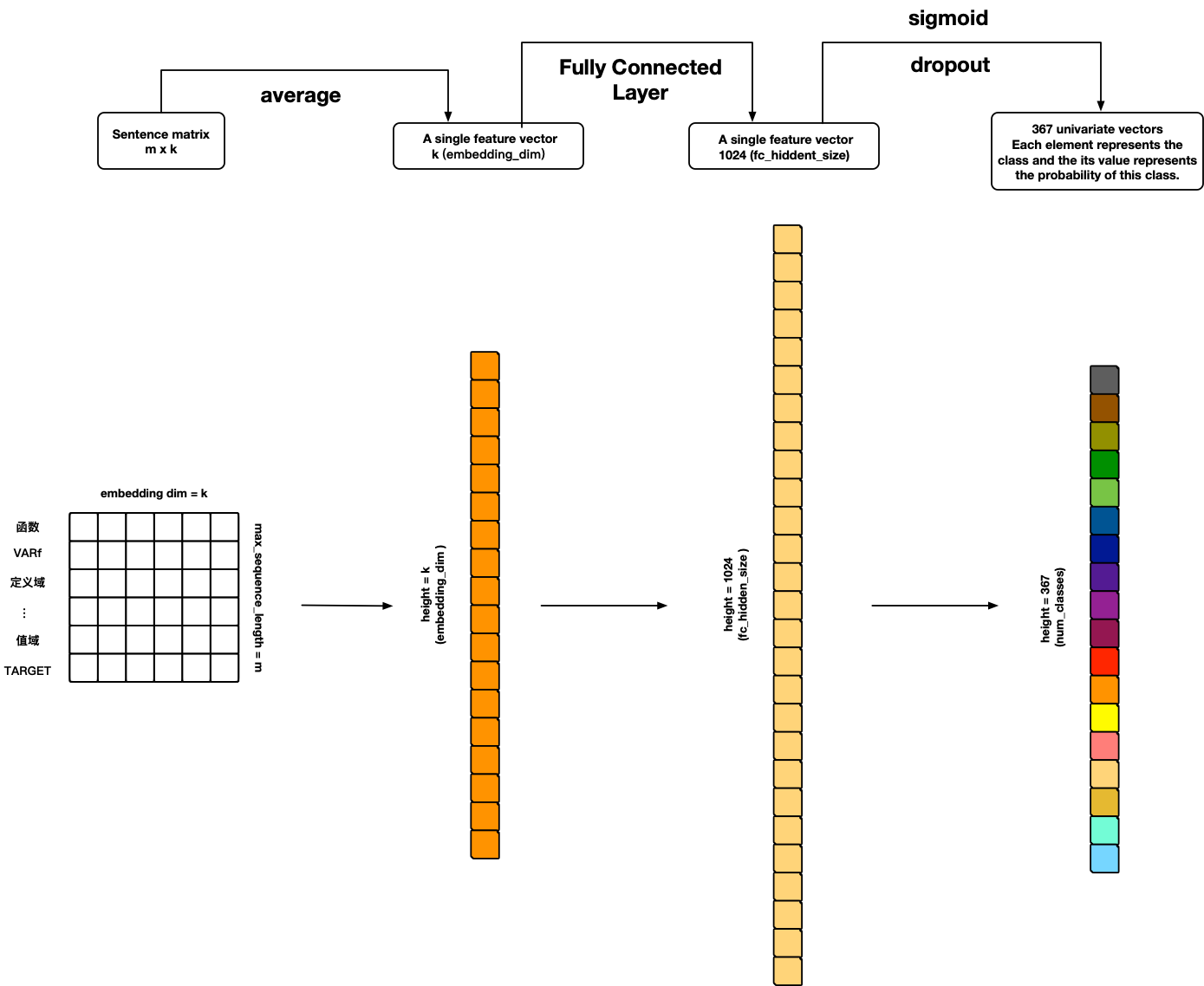
References:
- **Personal ideas **
---
### TextCNN
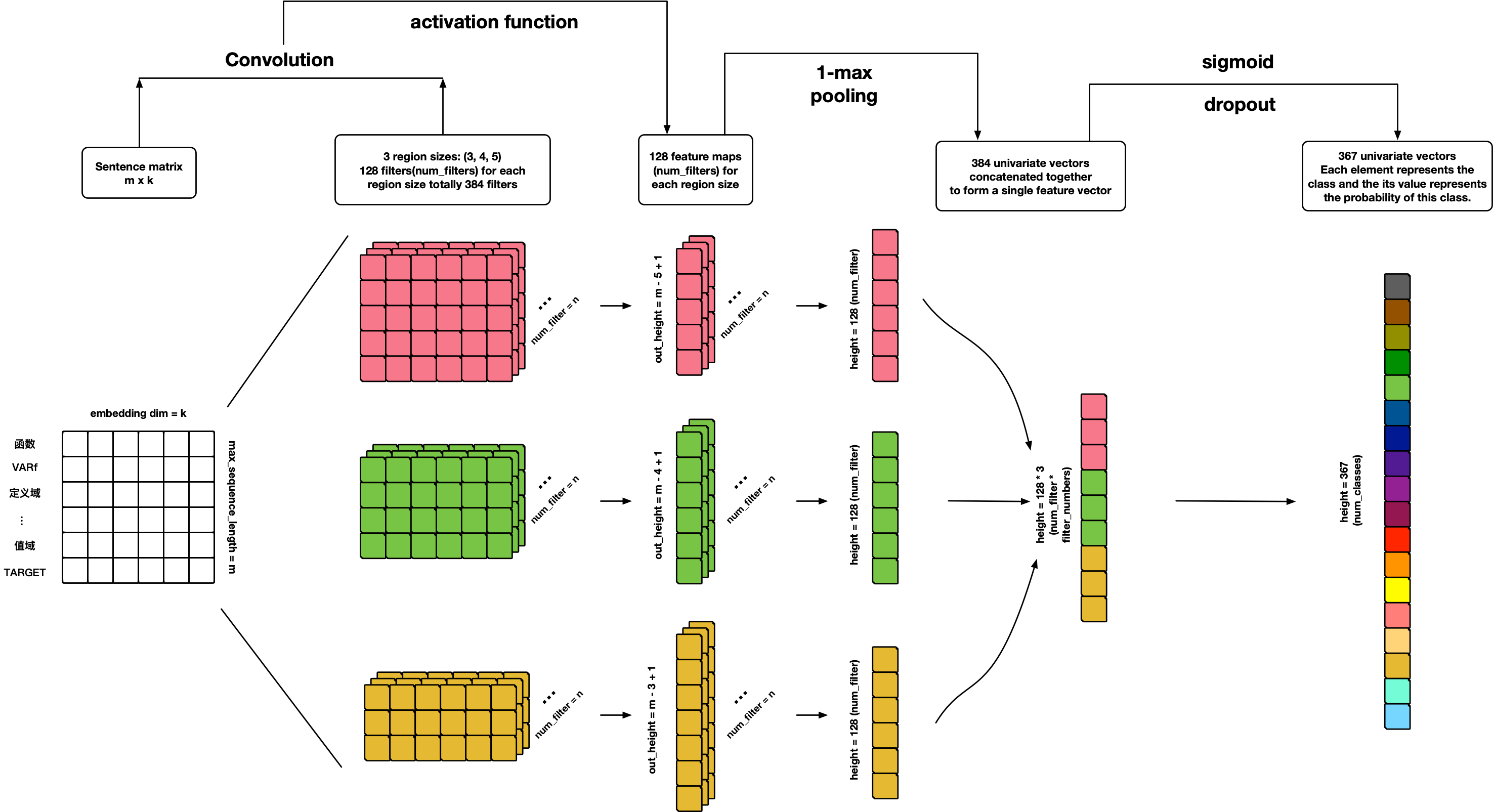
References:
- [Convolutional Neural Networks for Sentence Classification](http://arxiv.org/abs/1408.5882)
- [A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification](http://arxiv.org/abs/1510.03820)
---
### TextRNN
**Warning: Model can use but not finished yet ¤!**
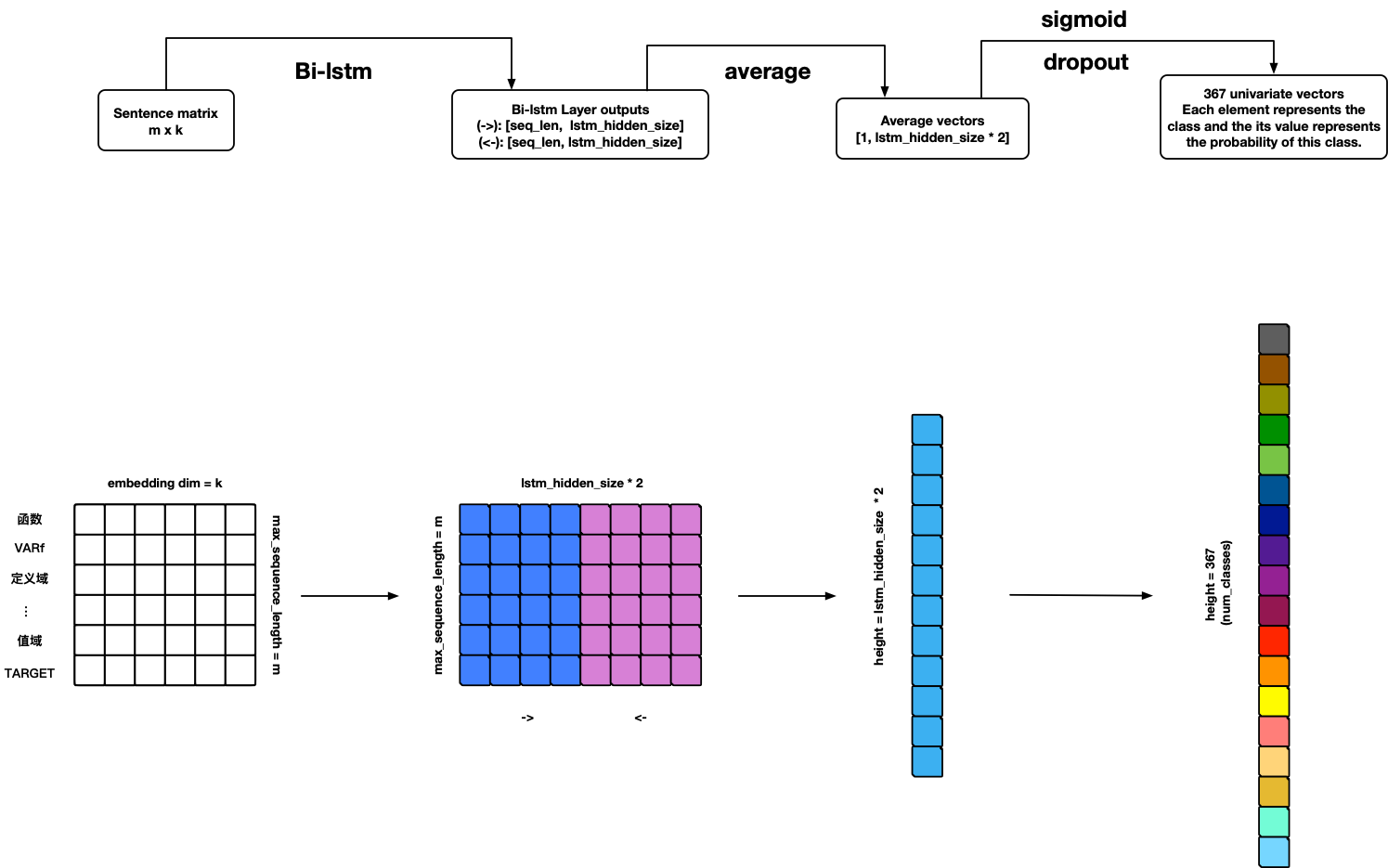
#### TODO
1. Add BN-LSTM cell unit.
2. Add attention.
References:
- [Recurrent Neural Network for Text Classification with Multi-Task Learning](http://www.***i.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552)
---
### TextCRNN
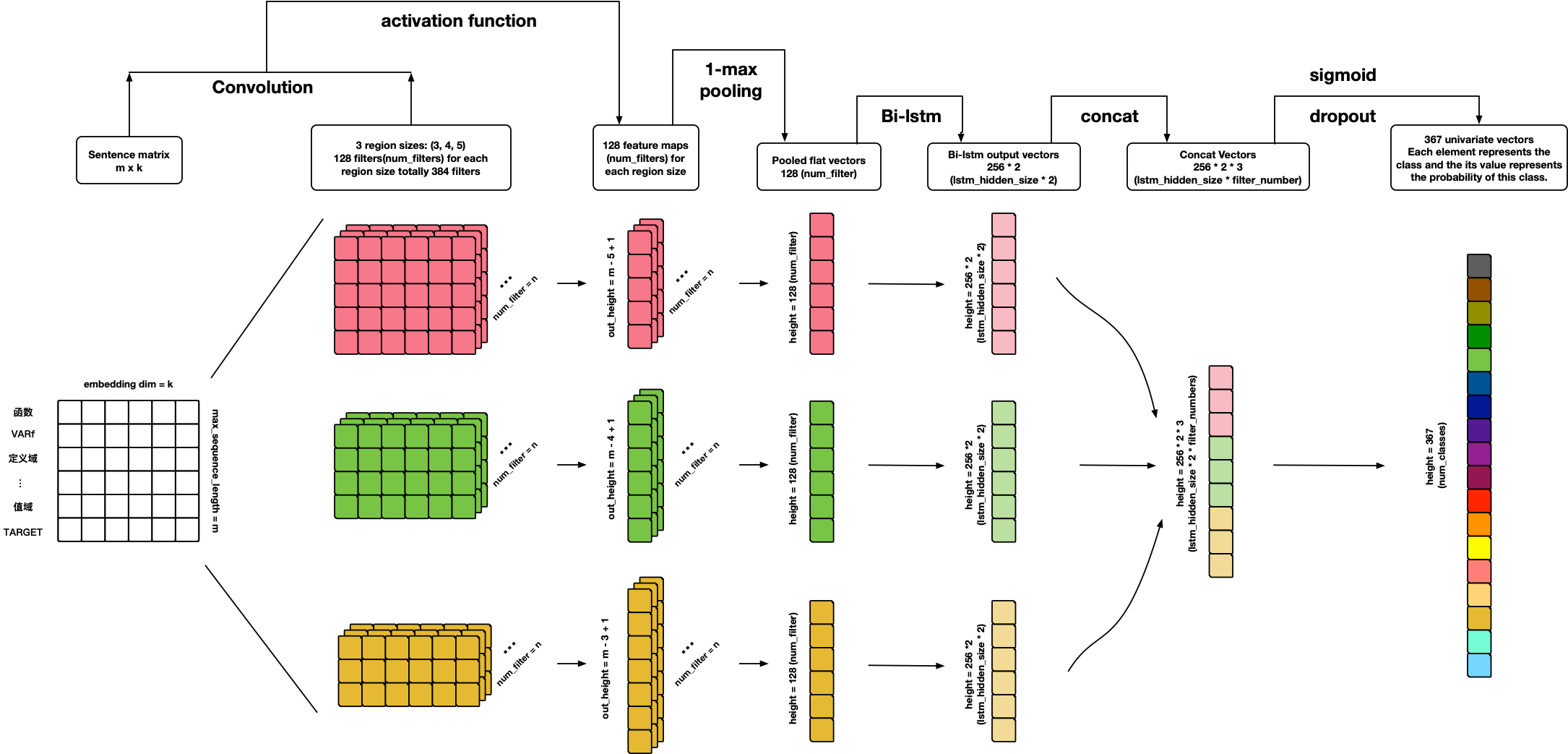
References:
- **Personal ideas **
---
### TextRCNN

References:
- **Personal ideas **
---
### TextHAN
References:
- [Hierarchical Attention Networks for Document Classification](https://www.cs.cmu.edu/~diyiy/docs/naacl16.pdf)
---
### TextSANN
**Warning: Model can use but not finished yet ¤!**
#### TODO
1. Add attention penalization loss.
2. Add visualization.
References:
- [A STRUCTURED SELF-ATTENTIVE SENTENCE EMBEDDING](https://arxiv.org/pdf/1703.03130.pdf)
---
## About Me
é¨Randolph
SCU SE Bachelor; USTC CS Master
Email: chinawolfman@hotmail.com
My Blog: [randolph.pro](http://randolph.pro)
LinkedIn: [randolph's linkedin](https://www.linkedin.com/in/randolph-%E9%BB%84%E5%A8%81/)
近期下载者:
相关文件:
收藏者: