Classifier
所属分类:数据挖掘/数据仓库
开发工具:Python
文件大小:930KB
下载次数:2
上传日期:2020-04-27 12:32:24
上 传 者:
huizyuan
说明: 基于python的数据挖掘算法,实现经典adult-data数据集的收入预测分类
(Based on the data mining algorithm of python, the revenue forecast and classification of classic adult data set is realized)
文件列表:
.idea\Adult-Data-Set-Classification-and-Classifier-Comparison-master.iml (464, 2019-12-05)
.idea\inspectionProfiles\profiles_settings.xml (174, 2019-12-05)
.idea\misc.xml (188, 2019-12-05)
.idea\modules.xml (383, 2019-12-05)
.idea\workspace.xml (2840, 2019-12-05)
adult.data (3974305, 2019-12-05)
classify.py (11918, 2019-12-05)
datasets\adult.data (3974305, 2019-12-05)
datasets\adult.names (5229, 2019-12-05)
datasets\adult.test (2003153, 2019-12-05)
datasets\Index (140, 2019-12-05)
datasets\old.adult.names (4267, 2019-12-05)
LICENSE (1066, 2018-07-07)
.idea\inspectionProfiles (0, 2019-12-05)
.idea (0, 2019-12-05)
datasets (0, 2019-12-05)
# Adult-Data-Set-Classification and Classifier Comparison
To run this program, use the code present in classify.py and dataset which can be obtained from https://drive.google.com/open?id=1y_9yAaLnC9aD_AOXp7jo1s9FqpABFSui.
- Place the data set and classify.py file in the same directory
- Open SPYDER IDE and open the classify.py
- Click on the run file button
Note
- In the code, the comments explains what each section does, for detailed explaination please refer to the report, which can be obtained from https://drive.google.com/open?id=1BdTz5lkCqEfZfInGNU8nHXYAsellqsdi
- If you want to see accuracy for every value of hyper parameter remove the hash symbol from line 77,94 and 111
- If you want to see accuracy and confusion matrix for every fold of each classifier remove the hash symbol from line 167,168 for SVM 185,186 for random forest 203,204 for KNN and 221,222 for naive bayes.
In this program I apply machine learning principals to predict weather income exceeds $50k per year on the Adult data set. I used four techniques to achieve better performance which includes choosing appropriate classifier, preprocessing techniques, parallel infrastructure and external libraries. This program will focus on proper use of each classifier by fine tuning the hyperparameter to achieve the best results, the classifiers include SVM, KNN, Random Forest, Gaussian Naive Bayes. The preprocessing techniques used to eliminate noise and inconsistency of data are standard scaler, label Encoder and quantile transformer. The best accuracy was achieved by random forest, this Classifier outperforms every other classifier as it makes multiple decision tree which prevents overfitting.
## Data Representation
Source: https://datascience52.wordpress.com/2016/12/21/visualisation-using-tableau/
## Execution Flow
The program will follow a systematic approach which can be summaried in the flow daigram below:
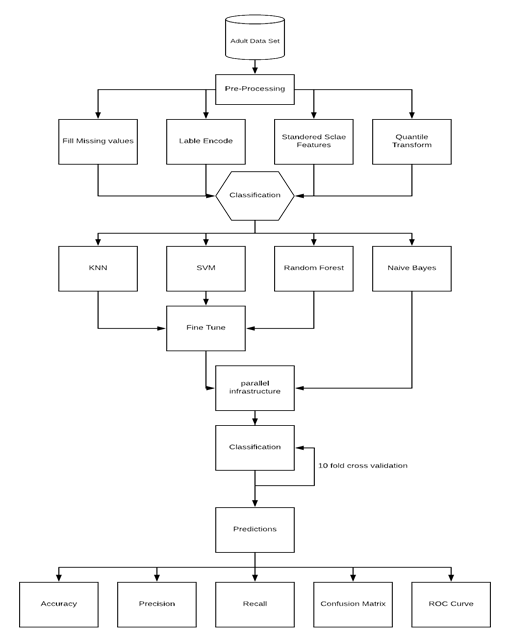
## Pre-Processing Techniques
The preprocessing techniques used in this report are:
- Quantile Transform
- Label encoder
- Standard scalar
- Fill N/A
## Classifiers
The classifiers used in the program are:
- KNN (k-nearest neighbors)
- SVM (Support vector machine)
- Random Forest
- Naive Bayes
For obtaining best accuracy for KNN, SVM, Random Forest I tried different values of hyperparameter. For each classifier’s value of hyperparameter I calculated the accuracy and picked the value which gave the maximum accuracy. I was also interested in finding the pattern of value of hyperparameter and accuracy, so I plotted a graph for it:

Also I applied 10-fold cross validation,the accuracy out of each evaluation is evaluated over 10 folds and averaged over the 10 fold period to get the desired result. The advantage of this method is that all the data is used to test and train the data thus makes the calculation accurate. This process is very memory and coputation intersive so I used threads to execute each fold of each classifier in parellel.
## Results


- The best result was obtained from random forest due to the fact that random forest overcomes the problem of overfitting by making multiple decision trees, as the dataset is baised (<=$50K 76%, >$50K 24%) decision tree clearly overcomes other classifiers
- Naive bayes algorithm performs well but is not accurate over the calculation period as the features in the dataset such as race , income, marital status may not be completely independent and on complete analysis no clear conclusion was drawn on these features. These features when grouped increase the amount of error in calculation. The reason why Gaussian Naive Bayes does not work well is because this data set has a lot of continuous variables on which this classifier does not work well.
- The reason why KNN performed well with this data set is because, the training data set was large so KNN could find more neighbors. But due to the fact the dataset has many irrelevant features the classifier couldn’t perform better.
- SVM performed very well because it has regularization parameter, which makes the user think about avoiding overfitting, but the execution time is very high which makes it less desirable to use.
By analysis of four different classification methods which are random forest, SVM, Naive Bayes and KNN algorithm. Out of these algorithms used the maximum accuracy obtained was of Random forest classification due to the nature of data given and the varied number of features in the dataset making it manageable and providing best execution with random forest. I obtained a maximum accuracy of 85.61% with 10-fold cross validation and using optimizations.
近期下载者:
相关文件:
收藏者: