Reinforcement-learning-with-tensorflow-master
说明: 实现强化学习,完成人工智能,实现机器学习,完成深度学习
(Realize reinforcement learning, artificial intelligence, machine learning and deep learning)
(Realize reinforcement learning, artificial intelligence, machine learning and deep learning)
文件列表:
LICENCE (1055, 2020-11-01)
RL_cover.jpg (69700, 2020-11-01)
contents (0, 2020-11-01)
contents\10_A3C (0, 2020-11-01)
contents\10_A3C\A3C_RNN.py (9429, 2020-11-01)
contents\10_A3C\A3C_continuous_action.py (8158, 2020-11-01)
contents\10_A3C\A3C_discrete_action.py (7894, 2020-11-01)
contents\10_A3C\A3C_distributed_tf.py (9199, 2020-11-01)
contents\11_Dyna_Q (0, 2020-11-01)
contents\11_Dyna_Q\RL_brain.py (3068, 2020-11-01)
contents\11_Dyna_Q\maze_env.py (3898, 2020-11-01)
contents\11_Dyna_Q\run_this.py (1500, 2020-11-01)
contents\12_Proximal_Policy_Optimization (0, 2020-11-01)
contents\12_Proximal_Policy_Optimization\DPPO.py (8270, 2020-11-01)
contents\12_Proximal_Policy_Optimization\discrete_DPPO.py (8817, 2020-11-01)
contents\12_Proximal_Policy_Optimization\simply_PPO.py (6467, 2020-11-01)
contents\1_command_line_reinforcement_learning (0, 2020-11-01)
contents\1_command_line_reinforcement_learning\treasure_on_right.py (3444, 2020-11-01)
contents\2_Q_Learning_maze (0, 2020-11-01)
contents\2_Q_Learning_maze\RL_brain.py (1851, 2020-11-01)
contents\2_Q_Learning_maze\__pycache__ (0, 2020-11-01)
contents\2_Q_Learning_maze\__pycache__\RL_brain.cpython-36.pyc (1832, 2020-11-01)
contents\2_Q_Learning_maze\__pycache__\maze_env.cpython-36.pyc (3630, 2020-11-01)
contents\2_Q_Learning_maze\maze_env.py (4307, 2020-11-01)
contents\2_Q_Learning_maze\run_this.py (1388, 2020-11-01)
contents\3_Sarsa_maze (0, 2020-11-01)
contents\3_Sarsa_maze\RL_brain.py (2711, 2020-11-01)
contents\3_Sarsa_maze\maze_env.py (4012, 2020-11-01)
contents\3_Sarsa_maze\run_this.py (1510, 2020-11-01)
contents\4_Sarsa_lambda_maze (0, 2020-11-01)
contents\4_Sarsa_lambda_maze\RL_brain.py (3177, 2020-11-01)
contents\4_Sarsa_lambda_maze\maze_env.py (4013, 2020-11-01)
contents\4_Sarsa_lambda_maze\run_this.py (1602, 2020-11-01)
contents\5.1_Double_DQN (0, 2020-11-01)
contents\5.1_Double_DQN\RL_brain.py (6678, 2020-11-01)
contents\5.1_Double_DQN\run_Pendulum.py (2133, 2020-11-01)
contents\5.2_Prioritized_Replay_DQN (0, 2020-11-01)
... ...
RL_cover.jpg (69700, 2020-11-01)
contents (0, 2020-11-01)
contents\10_A3C (0, 2020-11-01)
contents\10_A3C\A3C_RNN.py (9429, 2020-11-01)
contents\10_A3C\A3C_continuous_action.py (8158, 2020-11-01)
contents\10_A3C\A3C_discrete_action.py (7894, 2020-11-01)
contents\10_A3C\A3C_distributed_tf.py (9199, 2020-11-01)
contents\11_Dyna_Q (0, 2020-11-01)
contents\11_Dyna_Q\RL_brain.py (3068, 2020-11-01)
contents\11_Dyna_Q\maze_env.py (3898, 2020-11-01)
contents\11_Dyna_Q\run_this.py (1500, 2020-11-01)
contents\12_Proximal_Policy_Optimization (0, 2020-11-01)
contents\12_Proximal_Policy_Optimization\DPPO.py (8270, 2020-11-01)
contents\12_Proximal_Policy_Optimization\discrete_DPPO.py (8817, 2020-11-01)
contents\12_Proximal_Policy_Optimization\simply_PPO.py (6467, 2020-11-01)
contents\1_command_line_reinforcement_learning (0, 2020-11-01)
contents\1_command_line_reinforcement_learning\treasure_on_right.py (3444, 2020-11-01)
contents\2_Q_Learning_maze (0, 2020-11-01)
contents\2_Q_Learning_maze\RL_brain.py (1851, 2020-11-01)
contents\2_Q_Learning_maze\__pycache__ (0, 2020-11-01)
contents\2_Q_Learning_maze\__pycache__\RL_brain.cpython-36.pyc (1832, 2020-11-01)
contents\2_Q_Learning_maze\__pycache__\maze_env.cpython-36.pyc (3630, 2020-11-01)
contents\2_Q_Learning_maze\maze_env.py (4307, 2020-11-01)
contents\2_Q_Learning_maze\run_this.py (1388, 2020-11-01)
contents\3_Sarsa_maze (0, 2020-11-01)
contents\3_Sarsa_maze\RL_brain.py (2711, 2020-11-01)
contents\3_Sarsa_maze\maze_env.py (4012, 2020-11-01)
contents\3_Sarsa_maze\run_this.py (1510, 2020-11-01)
contents\4_Sarsa_lambda_maze (0, 2020-11-01)
contents\4_Sarsa_lambda_maze\RL_brain.py (3177, 2020-11-01)
contents\4_Sarsa_lambda_maze\maze_env.py (4013, 2020-11-01)
contents\4_Sarsa_lambda_maze\run_this.py (1602, 2020-11-01)
contents\5.1_Double_DQN (0, 2020-11-01)
contents\5.1_Double_DQN\RL_brain.py (6678, 2020-11-01)
contents\5.1_Double_DQN\run_Pendulum.py (2133, 2020-11-01)
contents\5.2_Prioritized_Replay_DQN (0, 2020-11-01)
... ...

# Reinforcement Learning Methods and Tutorials In these tutorials for reinforcement learning, it covers from the basic RL algorithms to advanced algorithms developed recent years. **If you speak Chinese, visit [莫烦 Python](https://mofanpy.com) or my [Youtube channel](https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg) for more.** **As many requests about making these tutorials available in English, please find them in this playlist:** ([https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba](https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba)) # Table of Contents * Tutorials * [Simple entry example](contents/1_command_line_reinforcement_learning) * [Q-learning](contents/2_Q_Learning_maze) * [Sarsa](contents/3_Sarsa_maze) * [Sarsa(lambda)](contents/4_Sarsa_lambda_maze) * [Deep Q Network (DQN)](contents/5_Deep_Q_Network) * [Using OpenAI Gym](contents/6_OpenAI_gym) * [Double DQN](contents/5.1_Double_DQN) * [DQN with Prioitized Experience Replay](contents/5.2_Prioritized_Replay_DQN) * [Dueling DQN](contents/5.3_Dueling_DQN) * [Policy Gradients](contents/7_Policy_gradient_softmax) * [Actor-Critic](contents/8_Actor_Critic_Advantage) * [Deep Deterministic Policy Gradient (DDPG)](contents/9_Deep_Deterministic_Policy_Gradient_DDPG) * [A3C](contents/10_A3C) * [Dyna-Q](contents/11_Dyna_Q) * [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization) * [Curiosity Model](/contents/Curiosity_Model), [Random Network Distillation (RND)](/contents/Curiosity_Model/Random_Network_Distillation.py) * [Some of my experiments](experiments) * [2D Car](experiments/2D_car) * [Robot arm](experiments/Robot_arm) * [BipedalWalker](experiments/Solve_BipedalWalker) * [LunarLander](experiments/Solve_LunarLander) # Some RL Networks ### [Deep Q Network](contents/5_Deep_Q_Network)
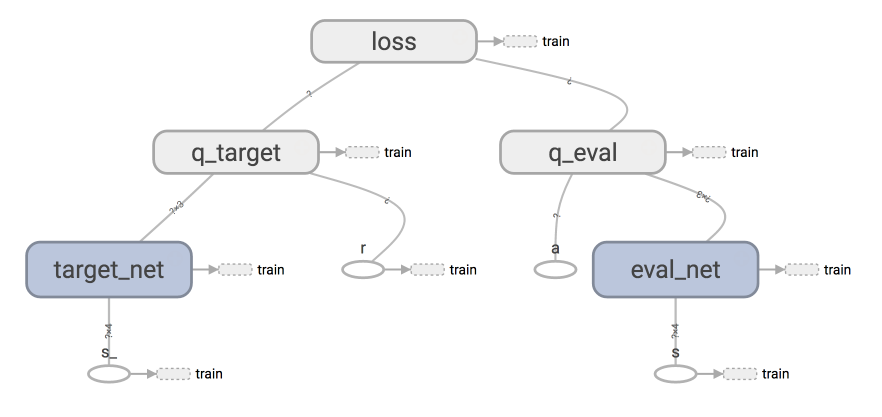 ### [Double DQN](contents/5.1_Double_DQN)
### [Double DQN](contents/5.1_Double_DQN)
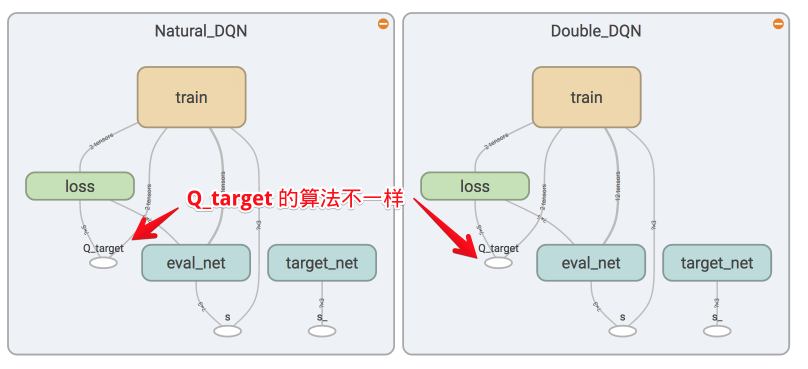 ### [Dueling DQN](contents/5.3_Dueling_DQN)
### [Dueling DQN](contents/5.3_Dueling_DQN)
 ### [Actor Critic](contents/8_Actor_Critic_Advantage)
### [Actor Critic](contents/8_Actor_Critic_Advantage)
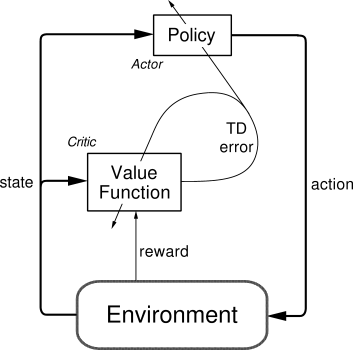 ### [Deep Deterministic Policy Gradient](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
### [Deep Deterministic Policy Gradient](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
 ### [A3C](contents/10_A3C)
### [A3C](contents/10_A3C)
 ### [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
### [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
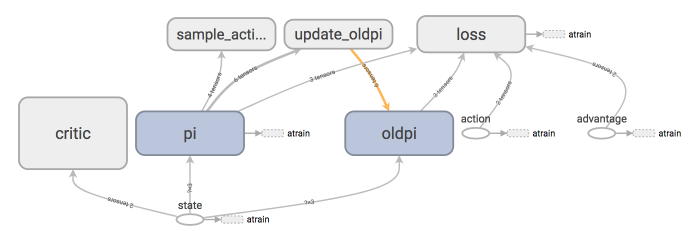 ### [Curiosity Model](/contents/Curiosity_Model)
### [Curiosity Model](/contents/Curiosity_Model)
 # Donation
*If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
# Donation
*If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*


近期下载者:
相关文件:
收藏者: