Classification-Model-BBC-News
所属分类:特征抽取
开发工具:Jupyter Notebook
文件大小:21757KB
下载次数:0
上传日期:2021-12-01 15:22:13
上 传 者:
sh-1993
说明: ...-的单词或TF-IDF矩阵,然后将数据拟合到各种分类模型中,对BBC新闻故事进行分类...
(I have been tasked to solve a text analytic problem using Python. I was given a dataset (bbc-text.csv) consists of 2225 documents from the BBC news website corresponding to stories in five topical areas from 2004-2005. The csv file consists of two columns, first being the “category”, which are the labels for each document: business, entertainmen...)
文件列表:
AA Assignment Presentation.pptx (9725322, 2021-12-01)
AA Assignment Report - Chen Han.docx (9902980, 2021-12-01)
AA_Assignment - Chen Han.ipynb (245343, 2021-12-01)
Model improvement ws.xlsx (8346, 2021-12-01)
bbc-text.csv (5057493, 2021-12-01)
imdb_export.csv (10156434, 2021-12-01)
stopwords.txt (2485, 2021-12-01)
## AA_Classification_Modelling_Project
## Description / Business understanding:
I was given a dataset (bbc-text.csv) consists of 2225 documents from the BBC news website corresponding to stories in five topical areas from 2004-2005.
The csv file consists of two columns, first being the “category”, which are the labels for each document: business, entertainment, politics, sport, and tech. Second column is “text”, which is the BBC news stories/ Document.
The goal to preprocess and transform the data into either bag-of-words or TF-IDF matrix, then fit the data into various classification models to classify the BBC news stories into different categories and lastly, comparing the performance of each model.
## Data Understanding and pre-processing
The first step will be text data pre-processing. Started off by extracting the data from the csv file and store it inside a data frame, followed by data cleansing using proper techniques such as removing stop words, stemming and lemmatizing.
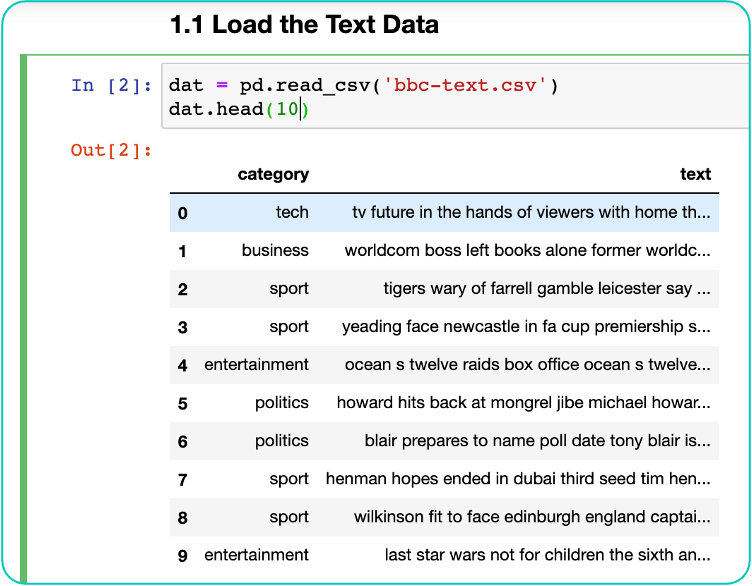
^ It has a two columns, first being the category column, which indicates which category that the text column belongs to

^Before cleansing

^After cleansing
## Data Tranformation
And lastly, the cleansed text data will be transformed into bag of words or TF-IDF matrix for classification modelling later.
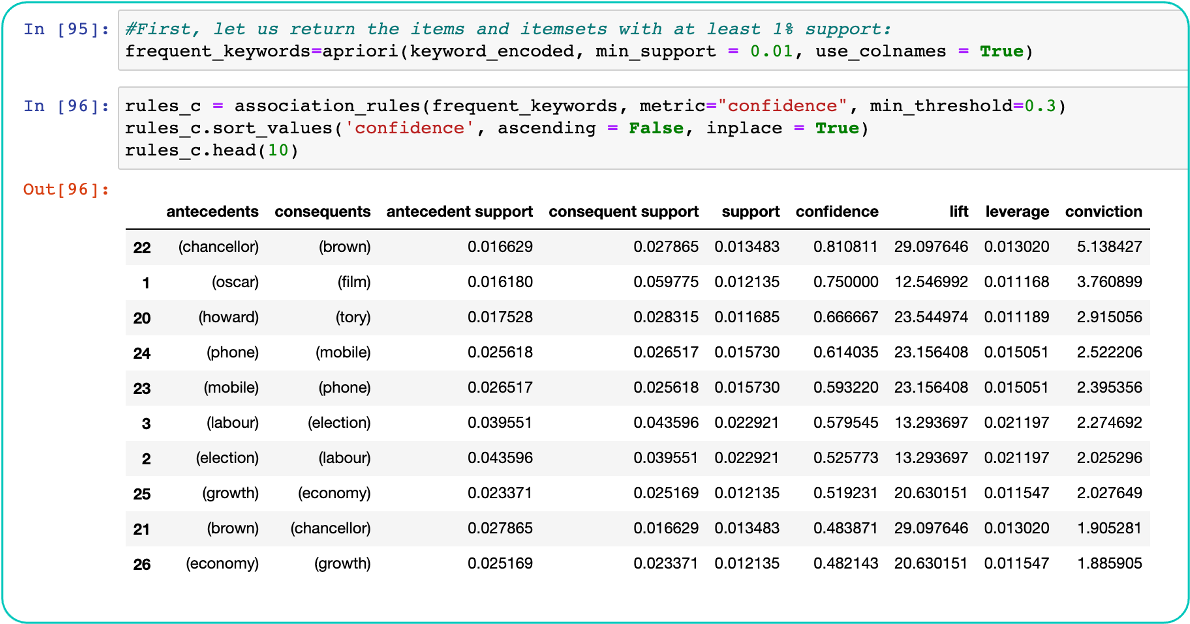
For step 2, it will be text data understanding, first by extracting the keywords from each document using TF-IDF matrix, the keywords extracted can be then used for analysis using Association Rule Mining.
The goal is to visualize and understand the associations between the keywords by category or by overall documents.
### Transform Data using bag-of-words matrix

### Transform Data using tf-idf value in matrix

### Extract Keywords

### Association Rule Mining
## Modelling (Classification model)
For step 3, it aims to use classification modellings on bag-of-word or TF-IDF matrix to classify the BBC news stories into different categories.
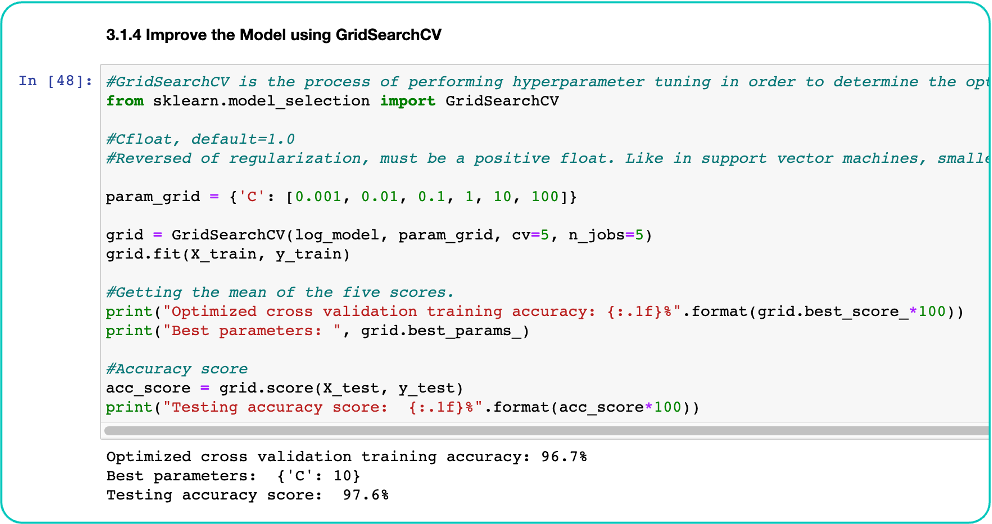
### 1. Using Logistic Regression (Word count)
### 2. SGD Classifier (word count)

### 3. Random Forest (Word count)

## Model Evaluation
And to evaluate the models performance using testing data and further improve the model performance by tuning model hyperparameters or further cleanse or transform the text data. The last step is to summarize the findings, which can be a collection of accuracy scores from different models using either bag-of-word or TF-IDF matrix and choose the most suitable model to use to classify future data. And finally, some possible improvements to be made.
### Comparing the 6 findings (including models using TF-IDF Matrix as input)
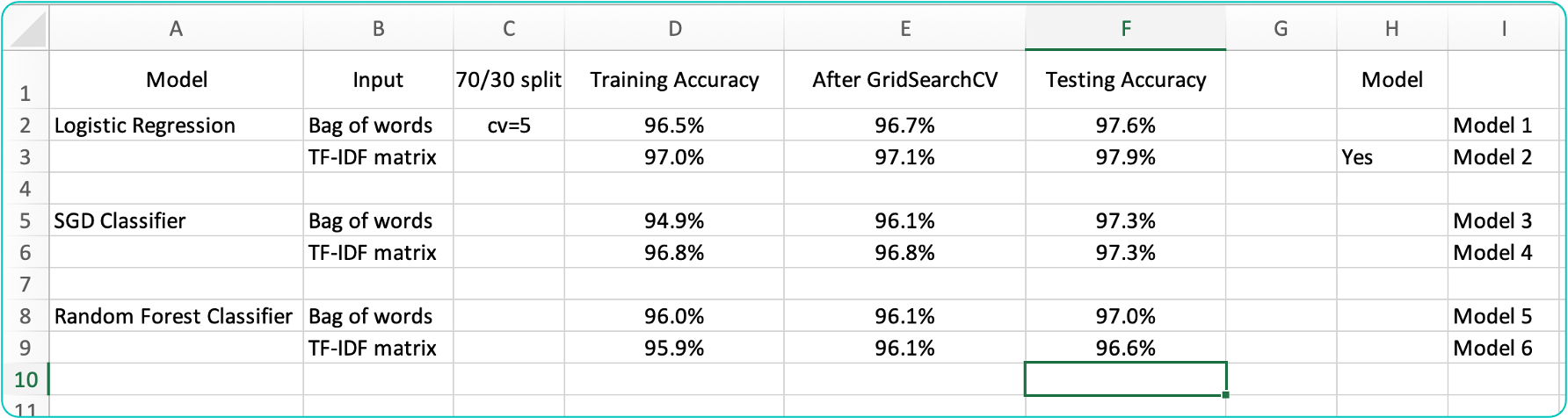
## Decision: Using Logistic Regression with IF-IDF Matrix as input is the best model for this problem.
近期下载者:
相关文件:
收藏者: