vit-pytorch
说明: vit pytorch,视觉转换器的实现,一种只需单个转换器即可在视觉分类中实现SOTA的简单方法...
(Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch)
(Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch)
文件列表:
LICENSE (1066, 2023-05-09)
MANIFEST.in (26, 2023-05-09)
examples (0, 2023-05-09)
examples\cats_and_dogs.ipynb (1111028, 2023-05-09)
images (0, 2023-05-09)
images\ats.png (202329, 2023-05-09)
images\cait.png (64648, 2023-05-09)
images\cross_vit.png (83793, 2023-05-09)
images\crossformer.png (173296, 2023-05-09)
images\crossformer2.png (242988, 2023-05-09)
images\cvt.png (66678, 2023-05-09)
images\dino.png (86133, 2023-05-09)
images\distill.png (50400, 2023-05-09)
images\esvit.png (195117, 2023-05-09)
images\learnable-memory-vit.png (111031, 2023-05-09)
images\levit.png (72784, 2023-05-09)
images\mae.png (202543, 2023-05-09)
images\max-vit.png (136409, 2023-05-09)
images\mbvit.png (211164, 2023-05-09)
images\mp3.png (530202, 2023-05-09)
images\nest.png (76438, 2023-05-09)
images\parallel-vit.png (14658, 2023-05-09)
images\patch_merger.png (55266, 2023-05-09)
images\pit.png (25058, 2023-05-09)
images\regionvit.png (96216, 2023-05-09)
images\regionvit2.png (56193, 2023-05-09)
images\scalable-vit-1.png (80843, 2023-05-09)
images\scalable-vit-2.png (63522, 2023-05-09)
images\sep-vit.png (145008, 2023-05-09)
images\simmim.png (373696, 2023-05-09)
images\t2t.png (111810, 2023-05-09)
images\twins_svt.png (112848, 2023-05-09)
... ...
MANIFEST.in (26, 2023-05-09)
examples (0, 2023-05-09)
examples\cats_and_dogs.ipynb (1111028, 2023-05-09)
images (0, 2023-05-09)
images\ats.png (202329, 2023-05-09)
images\cait.png (64648, 2023-05-09)
images\cross_vit.png (83793, 2023-05-09)
images\crossformer.png (173296, 2023-05-09)
images\crossformer2.png (242988, 2023-05-09)
images\cvt.png (66678, 2023-05-09)
images\dino.png (86133, 2023-05-09)
images\distill.png (50400, 2023-05-09)
images\esvit.png (195117, 2023-05-09)
images\learnable-memory-vit.png (111031, 2023-05-09)
images\levit.png (72784, 2023-05-09)
images\mae.png (202543, 2023-05-09)
images\max-vit.png (136409, 2023-05-09)
images\mbvit.png (211164, 2023-05-09)
images\mp3.png (530202, 2023-05-09)
images\nest.png (76438, 2023-05-09)
images\parallel-vit.png (14658, 2023-05-09)
images\patch_merger.png (55266, 2023-05-09)
images\pit.png (25058, 2023-05-09)
images\regionvit.png (96216, 2023-05-09)
images\regionvit2.png (56193, 2023-05-09)
images\scalable-vit-1.png (80843, 2023-05-09)
images\scalable-vit-2.png (63522, 2023-05-09)
images\sep-vit.png (145008, 2023-05-09)
images\simmim.png (373696, 2023-05-09)
images\t2t.png (111810, 2023-05-09)
images\twins_svt.png (112848, 2023-05-09)
... ...
 ## Table of Contents
- [Vision Transformer - Pytorch](https://github.com/lucidrains/vit-pytorch/blob/master/#vision-transformer---pytorch)
- [Install](https://github.com/lucidrains/vit-pytorch/blob/master/#install)
- [Usage](https://github.com/lucidrains/vit-pytorch/blob/master/#usage)
- [Parameters](https://github.com/lucidrains/vit-pytorch/blob/master/#parameters)
- [Simple ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#simple-vit)
- [Distillation](https://github.com/lucidrains/vit-pytorch/blob/master/#distillation)
- [Deep ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#deep-vit)
- [CaiT](https://github.com/lucidrains/vit-pytorch/blob/master/#cait)
- [Token-to-Token ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#token-to-token-vit)
- [CCT](https://github.com/lucidrains/vit-pytorch/blob/master/#cct)
- [Cross ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#cross-vit)
- [PiT](https://github.com/lucidrains/vit-pytorch/blob/master/#pit)
- [LeViT](https://github.com/lucidrains/vit-pytorch/blob/master/#levit)
- [CvT](https://github.com/lucidrains/vit-pytorch/blob/master/#cvt)
- [Twins SVT](https://github.com/lucidrains/vit-pytorch/blob/master/#twins-svt)
- [CrossFormer](https://github.com/lucidrains/vit-pytorch/blob/master/#crossformer)
- [RegionViT](https://github.com/lucidrains/vit-pytorch/blob/master/#regionvit)
- [ScalableViT](https://github.com/lucidrains/vit-pytorch/blob/master/#scalablevit)
- [SepViT](https://github.com/lucidrains/vit-pytorch/blob/master/#sepvit)
- [MaxViT](https://github.com/lucidrains/vit-pytorch/blob/master/#maxvit)
- [NesT](https://github.com/lucidrains/vit-pytorch/blob/master/#nest)
- [MobileViT](https://github.com/lucidrains/vit-pytorch/blob/master/#mobilevit)
- [Masked Autoencoder](https://github.com/lucidrains/vit-pytorch/blob/master/#masked-autoencoder)
- [Simple Masked Image Modeling](https://github.com/lucidrains/vit-pytorch/blob/master/#simple-masked-image-modeling)
- [Masked Patch Prediction](https://github.com/lucidrains/vit-pytorch/blob/master/#masked-patch-prediction)
- [Masked Position Prediction](https://github.com/lucidrains/vit-pytorch/blob/master/#masked-position-prediction)
- [Adaptive Token Sampling](https://github.com/lucidrains/vit-pytorch/blob/master/#adaptive-token-sampling)
- [Patch Merger](https://github.com/lucidrains/vit-pytorch/blob/master/#patch-merger)
- [Vision Transformer for Small Datasets](https://github.com/lucidrains/vit-pytorch/blob/master/#vision-transformer-for-small-datasets)
- [3D Vit](https://github.com/lucidrains/vit-pytorch/blob/master/#3d-vit)
- [ViVit](https://github.com/lucidrains/vit-pytorch/blob/master/#vivit)
- [Parallel ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#parallel-vit)
- [Learnable Memory ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#learnable-memory-vit)
- [Dino](https://github.com/lucidrains/vit-pytorch/blob/master/#dino)
- [EsViT](https://github.com/lucidrains/vit-pytorch/blob/master/#esvit)
- [Accessing Attention](https://github.com/lucidrains/vit-pytorch/blob/master/#accessing-attention)
- [Research Ideas](https://github.com/lucidrains/vit-pytorch/blob/master/#research-ideas)
* [Efficient Attention](https://github.com/lucidrains/vit-pytorch/blob/master/#efficient-attention)
* [Combining with other Transformer improvements](https://github.com/lucidrains/vit-pytorch/blob/master/#combining-with-other-transformer-improvements)
- [FAQ](https://github.com/lucidrains/vit-pytorch/blob/master/#faq)
- [Resources](https://github.com/lucidrains/vit-pytorch/blob/master/#resources)
- [Citations](https://github.com/lucidrains/vit-pytorch/blob/master/#citations)
## Vision Transformer - Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch. Significance is further explained in Yannic Kilcher's video. There's really not much to code here, but may as well lay it out for everyone so we expedite the attention revolution.
For a Pytorch implementation with pretrained models, please see Ross Wightman's repository here.
The official Jax repository is here.
A tensorflow2 translation also exists here, created by research scientist Junho Kim!
Flax translation by Enrico Shippole!
## Install
```bash
$ pip install vit-pytorch
```
## Usage
```python
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
```
## Parameters
- `image_size`: int.
Image size. If you have rectangular images, make sure your image size is the maximum of the width and height
- `patch_size`: int.
Number of patches. `image_size` must be divisible by `patch_size`.
The number of patches is: ` n = (image_size // patch_size) ** 2` and `n` **must be greater than 16**.
- `num_classes`: int.
Number of classes to classify.
- `dim`: int.
Last dimension of output tensor after linear transformation `nn.Linear(..., dim)`.
- `depth`: int.
Number of Transformer blocks.
- `heads`: int.
Number of heads in Multi-head Attention layer.
- `mlp_dim`: int.
Dimension of the MLP (FeedForward) layer.
- `channels`: int, default `3`.
Number of image's channels.
- `dropout`: float between `[0, 1]`, default `0.`.
Dropout rate.
- `emb_dropout`: float between `[0, 1]`, default `0`.
Embedding dropout rate.
- `pool`: string, either `cls` token pooling or `mean` pooling
## Simple ViT
An update from some of the same authors of the original paper proposes simplifications to `ViT` that allows it to train faster and better.
Among these simplifications include 2d sinusoidal positional embedding, global average pooling (no CLS token), no dropout, batch sizes of 1024 rather than 4096, and use of RandAugment and MixUp augmentations. They also show that a simple linear at the end is not significantly worse than the original MLP head
You can use it by importing the `SimpleViT` as shown below
```python
import torch
from vit_pytorch import SimpleViT
v = SimpleViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
```
## Distillation
## Table of Contents
- [Vision Transformer - Pytorch](https://github.com/lucidrains/vit-pytorch/blob/master/#vision-transformer---pytorch)
- [Install](https://github.com/lucidrains/vit-pytorch/blob/master/#install)
- [Usage](https://github.com/lucidrains/vit-pytorch/blob/master/#usage)
- [Parameters](https://github.com/lucidrains/vit-pytorch/blob/master/#parameters)
- [Simple ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#simple-vit)
- [Distillation](https://github.com/lucidrains/vit-pytorch/blob/master/#distillation)
- [Deep ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#deep-vit)
- [CaiT](https://github.com/lucidrains/vit-pytorch/blob/master/#cait)
- [Token-to-Token ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#token-to-token-vit)
- [CCT](https://github.com/lucidrains/vit-pytorch/blob/master/#cct)
- [Cross ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#cross-vit)
- [PiT](https://github.com/lucidrains/vit-pytorch/blob/master/#pit)
- [LeViT](https://github.com/lucidrains/vit-pytorch/blob/master/#levit)
- [CvT](https://github.com/lucidrains/vit-pytorch/blob/master/#cvt)
- [Twins SVT](https://github.com/lucidrains/vit-pytorch/blob/master/#twins-svt)
- [CrossFormer](https://github.com/lucidrains/vit-pytorch/blob/master/#crossformer)
- [RegionViT](https://github.com/lucidrains/vit-pytorch/blob/master/#regionvit)
- [ScalableViT](https://github.com/lucidrains/vit-pytorch/blob/master/#scalablevit)
- [SepViT](https://github.com/lucidrains/vit-pytorch/blob/master/#sepvit)
- [MaxViT](https://github.com/lucidrains/vit-pytorch/blob/master/#maxvit)
- [NesT](https://github.com/lucidrains/vit-pytorch/blob/master/#nest)
- [MobileViT](https://github.com/lucidrains/vit-pytorch/blob/master/#mobilevit)
- [Masked Autoencoder](https://github.com/lucidrains/vit-pytorch/blob/master/#masked-autoencoder)
- [Simple Masked Image Modeling](https://github.com/lucidrains/vit-pytorch/blob/master/#simple-masked-image-modeling)
- [Masked Patch Prediction](https://github.com/lucidrains/vit-pytorch/blob/master/#masked-patch-prediction)
- [Masked Position Prediction](https://github.com/lucidrains/vit-pytorch/blob/master/#masked-position-prediction)
- [Adaptive Token Sampling](https://github.com/lucidrains/vit-pytorch/blob/master/#adaptive-token-sampling)
- [Patch Merger](https://github.com/lucidrains/vit-pytorch/blob/master/#patch-merger)
- [Vision Transformer for Small Datasets](https://github.com/lucidrains/vit-pytorch/blob/master/#vision-transformer-for-small-datasets)
- [3D Vit](https://github.com/lucidrains/vit-pytorch/blob/master/#3d-vit)
- [ViVit](https://github.com/lucidrains/vit-pytorch/blob/master/#vivit)
- [Parallel ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#parallel-vit)
- [Learnable Memory ViT](https://github.com/lucidrains/vit-pytorch/blob/master/#learnable-memory-vit)
- [Dino](https://github.com/lucidrains/vit-pytorch/blob/master/#dino)
- [EsViT](https://github.com/lucidrains/vit-pytorch/blob/master/#esvit)
- [Accessing Attention](https://github.com/lucidrains/vit-pytorch/blob/master/#accessing-attention)
- [Research Ideas](https://github.com/lucidrains/vit-pytorch/blob/master/#research-ideas)
* [Efficient Attention](https://github.com/lucidrains/vit-pytorch/blob/master/#efficient-attention)
* [Combining with other Transformer improvements](https://github.com/lucidrains/vit-pytorch/blob/master/#combining-with-other-transformer-improvements)
- [FAQ](https://github.com/lucidrains/vit-pytorch/blob/master/#faq)
- [Resources](https://github.com/lucidrains/vit-pytorch/blob/master/#resources)
- [Citations](https://github.com/lucidrains/vit-pytorch/blob/master/#citations)
## Vision Transformer - Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch. Significance is further explained in Yannic Kilcher's video. There's really not much to code here, but may as well lay it out for everyone so we expedite the attention revolution.
For a Pytorch implementation with pretrained models, please see Ross Wightman's repository here.
The official Jax repository is here.
A tensorflow2 translation also exists here, created by research scientist Junho Kim!
Flax translation by Enrico Shippole!
## Install
```bash
$ pip install vit-pytorch
```
## Usage
```python
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
```
## Parameters
- `image_size`: int.
Image size. If you have rectangular images, make sure your image size is the maximum of the width and height
- `patch_size`: int.
Number of patches. `image_size` must be divisible by `patch_size`.
The number of patches is: ` n = (image_size // patch_size) ** 2` and `n` **must be greater than 16**.
- `num_classes`: int.
Number of classes to classify.
- `dim`: int.
Last dimension of output tensor after linear transformation `nn.Linear(..., dim)`.
- `depth`: int.
Number of Transformer blocks.
- `heads`: int.
Number of heads in Multi-head Attention layer.
- `mlp_dim`: int.
Dimension of the MLP (FeedForward) layer.
- `channels`: int, default `3`.
Number of image's channels.
- `dropout`: float between `[0, 1]`, default `0.`.
Dropout rate.
- `emb_dropout`: float between `[0, 1]`, default `0`.
Embedding dropout rate.
- `pool`: string, either `cls` token pooling or `mean` pooling
## Simple ViT
An update from some of the same authors of the original paper proposes simplifications to `ViT` that allows it to train faster and better.
Among these simplifications include 2d sinusoidal positional embedding, global average pooling (no CLS token), no dropout, batch sizes of 1024 rather than 4096, and use of RandAugment and MixUp augmentations. They also show that a simple linear at the end is not significantly worse than the original MLP head
You can use it by importing the `SimpleViT` as shown below
```python
import torch
from vit_pytorch import SimpleViT
v = SimpleViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
```
## Distillation
 A recent paper has shown that use of a distillation token for distilling knowledge from convolutional nets to vision transformer can yield small and efficient vision transformers. This repository offers the means to do distillation easily.
ex. distilling from Resnet50 (or any teacher) to a vision transformer
```python
import torch
from torchvision.models import resnet50
from vit_pytorch.distill import DistillableViT, DistillWrapper
teacher = resnet50(pretrained = True)
v = DistillableViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
distiller = DistillWrapper(
student = v,
teacher = teacher,
temperature = 3, # temperature of distillation
alpha = 0.5, # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch.randn(2, 3, 256, 256)
labels = torch.randint(0, 1000, (2,))
loss = distiller(img, labels)
loss.backward()
# after lots of training above ...
pred = v(img) # (2, 1000)
```
The `DistillableViT` class is identical to `ViT` except for how the forward pass is handled, so you should be able to load the parameters back to `ViT` after you have completed distillation training.
You can also use the handy `.to_vit` method on the `DistillableViT` instance to get back a `ViT` instance.
```python
v = v.to_vit()
type(v) #
A recent paper has shown that use of a distillation token for distilling knowledge from convolutional nets to vision transformer can yield small and efficient vision transformers. This repository offers the means to do distillation easily.
ex. distilling from Resnet50 (or any teacher) to a vision transformer
```python
import torch
from torchvision.models import resnet50
from vit_pytorch.distill import DistillableViT, DistillWrapper
teacher = resnet50(pretrained = True)
v = DistillableViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
distiller = DistillWrapper(
student = v,
teacher = teacher,
temperature = 3, # temperature of distillation
alpha = 0.5, # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch.randn(2, 3, 256, 256)
labels = torch.randint(0, 1000, (2,))
loss = distiller(img, labels)
loss.backward()
# after lots of training above ...
pred = v(img) # (2, 1000)
```
The `DistillableViT` class is identical to `ViT` except for how the forward pass is handled, so you should be able to load the parameters back to `ViT` after you have completed distillation training.
You can also use the handy `.to_vit` method on the `DistillableViT` instance to get back a `ViT` instance.
```python
v = v.to_vit()
type(v) #  This paper proposes that the first couple layers should downsample the image sequence by unfolding, leading to overlapping image data in each token as shown in the figure above. You can use this variant of the `ViT` as follows.
```python
import torch
from vit_pytorch.t2t import T2TViT
v = T2TViT(
dim = 512,
image_size = 224,
depth = 5,
heads = 8,
mlp_dim = 512,
num_classes = 1000,
t2t_layers = ((7, 4), (3, 2), (3, 2)) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
```
## CCT
This paper proposes that the first couple layers should downsample the image sequence by unfolding, leading to overlapping image data in each token as shown in the figure above. You can use this variant of the `ViT` as follows.
```python
import torch
from vit_pytorch.t2t import T2TViT
v = T2TViT(
dim = 512,
image_size = 224,
depth = 5,
heads = 8,
mlp_dim = 512,
num_classes = 1000,
t2t_layers = ((7, 4), (3, 2), (3, 2)) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
```
## CCT
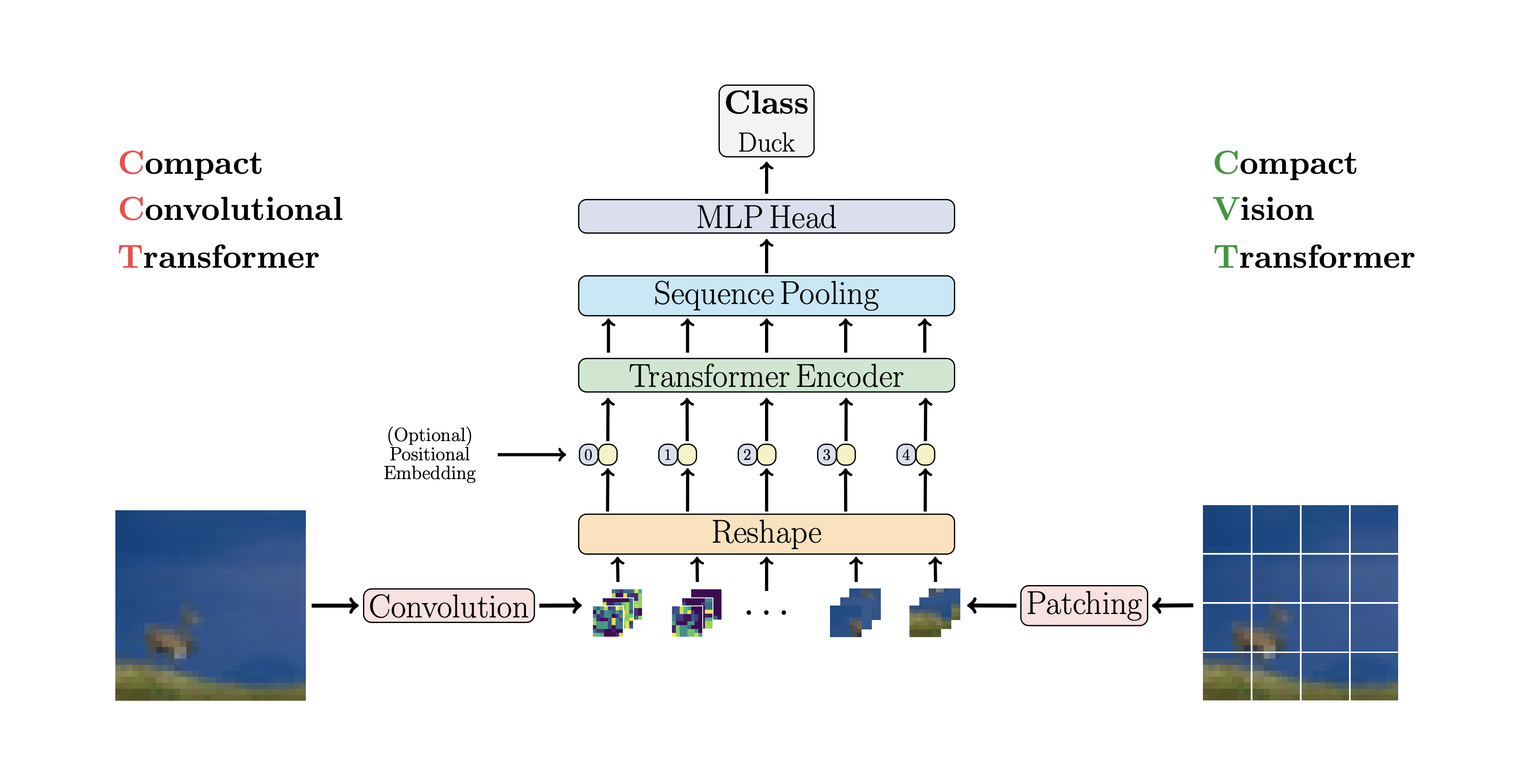 CCT proposes compact transformers
by using convolutions instead of patching and performing sequence pooling. This
allows for CCT to have high accuracy and a low number of parameters.
You can use this with two methods
```python
import torch
from vit_pytorch.cct import CCT
cct = CCT(
img_size = (224, 448),
embedding_dim = 384,
n_conv_layers = 2,
kernel_size = 7,
stride = 2,
padding = 3,
pooling_kernel_size = 3,
pooling_stride = 2,
pooling_padding = 1,
num_layers = 14,
num_heads = 6,
mlp_ratio = 3.,
num_classes = 1000,
positional_embedding = 'learnable', # ['sine', 'learnable', 'none']
)
img = torch.randn(1, 3, 224, 448)
pred = cct(img) # (1, 1000)
```
Alternatively you can use one of several pre-defined models `[2,4,6,7,8,14,16]`
which pre-define the number of layers, number of attention heads, the mlp ratio,
and the embedding dimension.
```python
import torch
from vit_pytorch.cct import cct_14
cct = cct_14(
img_size = 224,
n_conv_layers = 1,
kernel_size = 7,
stride = 2,
padding = 3,
pooling_kernel_size = 3,
pooling_stride = 2,
pooling_padding = 1,
num_classes = 1000,
positional_embedding = 'learnable', # ['sine', 'learnable', 'none']
)
```
Official
Repository includes links to pretrained model checkpoints.
## Cross ViT
CCT proposes compact transformers
by using convolutions instead of patching and performing sequence pooling. This
allows for CCT to have high accuracy and a low number of parameters.
You can use this with two methods
```python
import torch
from vit_pytorch.cct import CCT
cct = CCT(
img_size = (224, 448),
embedding_dim = 384,
n_conv_layers = 2,
kernel_size = 7,
stride = 2,
padding = 3,
pooling_kernel_size = 3,
pooling_stride = 2,
pooling_padding = 1,
num_layers = 14,
num_heads = 6,
mlp_ratio = 3.,
num_classes = 1000,
positional_embedding = 'learnable', # ['sine', 'learnable', 'none']
)
img = torch.randn(1, 3, 224, 448)
pred = cct(img) # (1, 1000)
```
Alternatively you can use one of several pre-defined models `[2,4,6,7,8,14,16]`
which pre-define the number of layers, number of attention heads, the mlp ratio,
and the embedding dimension.
```python
import torch
from vit_pytorch.cct import cct_14
cct = cct_14(
img_size = 224,
n_conv_layers = 1,
kernel_size = 7,
stride = 2,
padding = 3,
pooling_kernel_size = 3,
pooling_stride = 2,
pooling_padding = 1,
num_classes = 1000,
positional_embedding = 'learnable', # ['sine', 'learnable', 'none']
)
```
Official
Repository includes links to pretrained model checkpoints.
## Cross ViT
 This paper proposes to have two vision transformers processing the image at different scales, cross attending to one every so often. They show improvements on top of the base vision transformer.
```python
import torch
from vit_pytorch.cross_vit import CrossViT
v = CrossViT(
image_size = 256,
num_classes = 1000,
depth = 4, # number of multi-scale encoding blocks
sm_dim = 192, # high res dimension
sm_patch_size = 16, # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2, # high res depth
sm_enc_heads = 8, # high res heads
sm_enc_mlp_dim = 2048, # high res feedforward dimension
lg_dim = 384, # low res dimension
lg_patch_size = ***, # low res patch size
lg_enc_depth = 3, # low res depth
lg_enc_heads = 8, # low res heads
lg_enc_mlp_dim = 2048, # low res feedforward dimensions
cross_attn_depth = 2, # cross attention rounds
cross_attn_heads = 8, # cross attention heads
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
pred = v(img) # (1, 1000)
```
## PiT
This paper proposes to have two vision transformers processing the image at different scales, cross attending to one every so often. They show improvements on top of the base vision transformer.
```python
import torch
from vit_pytorch.cross_vit import CrossViT
v = CrossViT(
image_size = 256,
num_classes = 1000,
depth = 4, # number of multi-scale encoding blocks
sm_dim = 192, # high res dimension
sm_patch_size = 16, # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2, # high res depth
sm_enc_heads = 8, # high res heads
sm_enc_mlp_dim = 2048, # high res feedforward dimension
lg_dim = 384, # low res dimension
lg_patch_size = ***, # low res patch size
lg_enc_depth = 3, # low res depth
lg_enc_heads = 8, # low res heads
lg_enc_mlp_dim = 2048, # low res feedforward dimensions
cross_attn_depth = 2, # cross attention rounds
cross_attn_heads = 8, # cross attention heads
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
pred = v(img) # (1, 1000)
```
## PiT
 This paper proposes to downsample the tokens through a pooling procedure using depth-wise convolutions.
```python
import torch
from vit_pytorch.pit import PiT
v = PiT(
image_size = 224,
patch_size = 14,
dim = 256,
num_classes = 1000,
depth = (3, 3, 3), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
```
## LeViT
This paper proposes to downsample the tokens through a pooling procedure using depth-wise convolutions.
```python
import torch
from vit_pytorch.pit import PiT
v = PiT(
image_size = 224,
patch_size = 14,
dim = 256,
num_classes = 1000,
depth = (3, 3, 3), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
```
## LeViT
 This paper proposes a number of changes, including (1) convolutional embedding instead of patch-wise projection (2) downsampling in stages (3) extra non-linearity in attention (4) 2d relative positional biases instead of initial absolute positional bias (5) batchnorm in place of layernorm.
Official repository
```python
import torch
from vit_pytorch.levit import LeViT
levit = LeViT(
image_size = 224,
num_classes = 1000,
stages = 3, # number of stages
dim = (256, 384, 512), # dimensions at each stage
depth = 4, # transformer of depth 4 at each stage
heads = (4, 6, 8), # heads at each stage
mlp_mult = 2,
dropout = 0.1
)
img = torch.randn(1, 3, 224, 224)
levit(img) # (1, 1000)
```
## CvT
This paper proposes a number of changes, including (1) convolutional embedding instead of patch-wise projection (2) downsampling in stages (3) extra non-linearity in attention (4) 2d relative positional biases instead of initial absolute positional bias (5) batchnorm in place of layernorm.
Official repository
```python
import torch
from vit_pytorch.levit import LeViT
levit = LeViT(
image_size = 224,
num_classes = 1000,
stages = 3, # number of stages
dim = (256, 384, 512), # dimensions at each stage
depth = 4, # transformer of depth 4 at each stage
heads = (4, 6, 8), # heads at each stage
mlp_mult = 2,
dropout = 0.1
)
img = torch.randn(1, 3, 224, 224)
levit(img) # (1, 1000)
```
## CvT
 This paper proposes mixing convolutions and attention. Specifically, convolutions are used to embed and downsample the image / feature map in three stages. Depthwise-convoltion is also used to project the queries, keys, and values for attention.
```python
import torch
from vit_pytorch.cvt import CvT
v = CvT(
num_classes = 1000,
s1_emb_dim = ***, # stage 1 - dimension
s1_emb_kernel = 7, # stage 1 - conv kernel
s1_emb_stride = 4, # stage 1 - conv stride
s1_proj_kernel = 3, # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2, # stage 1 - attention key / value projection stride
s1_heads = 1, # stage 1 - heads
s1_depth = 1, # stage 1 - depth
s1_mlp_mult = 4, # stage 1 - feedforward expansion factor
s2_emb_dim = 192, # stage 2 - (same as above)
s2_emb_kernel = 3,
s2_emb_stride = 2,
s2_proj_kernel = 3,
s2_kv_proj_stride = 2,
s2_heads = 3,
s2_depth = 2,
s2_mlp_mult = 4,
s3_emb_dim = 384, # stage 3 - (same as above)
s3_emb_kernel = 3,
s3_emb_stride = 2,
s3_proj_kernel = 3,
s3_kv_proj_stride = 2,
s3_heads = 4,
s3_depth = 10,
s3_mlp_mult = 4,
dropout = 0.
)
img = torch.randn(1, 3, 224, 224)
pred = v(img) # (1, 1000)
```
## Twins SVT
This paper proposes mixing convolutions and attention. Specifically, convolutions are used to embed and downsample the image / feature map in three stages. Depthwise-convoltion is also used to project the queries, keys, and values for attention.
```python
import torch
from vit_pytorch.cvt import CvT
v = CvT(
num_classes = 1000,
s1_emb_dim = ***, # stage 1 - dimension
s1_emb_kernel = 7, # stage 1 - conv kernel
s1_emb_stride = 4, # stage 1 - conv stride
s1_proj_kernel = 3, # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2, # stage 1 - attention key / value projection stride
s1_heads = 1, # stage 1 - heads
s1_depth = 1, # stage 1 - depth
s1_mlp_mult = 4, # stage 1 - feedforward expansion factor
s2_emb_dim = 192, # stage 2 - (same as above)
s2_emb_kernel = 3,
s2_emb_stride = 2,
s2_proj_kernel = 3,
s2_kv_proj_stride = 2,
s2_heads = 3,
s2_depth = 2,
s2_mlp_mult = 4,
s3_emb_dim = 384, # stage 3 - (same as above)
s3_emb_kernel = 3,
s3_emb_stride = 2,
s3_proj_kernel = 3,
s3_kv_proj_stride = 2,
s3_heads = 4,
s3_depth = 10,
s3_mlp_mult = 4,
dropout = 0.
)
img = torch.randn(1, 3, 224, 224)
pred = v(img) # (1, 1000)
```
## Twins SVT
 This paper proposes mixing local and global attention, along with position encoding generator (proposed in CPVT) and global average pooling, to achieve the same results as Swin, without the extra complexity of shifted windows, CLS tokens, nor positional embeddings.
```python
import torch
from vit_pytorch.twins_svt import TwinsSVT
model = TwinsSVT(
num_classes = 1000, # number of output classes
s1_emb_dim = ***, # stage 1 - patch embedding projected dimension
s1_patch_size = 4, # stage 1 - patch size for patch embedding
s1_local_patch_size = 7, # stage 1 - patch size for local attention
s1_global_k = 7, # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1, # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128, # stage 2 (same as above)
s2_patch_size = 2,
s2_local_patch_size = 7,
s2_global_k = 7,
s2_depth = 1,
s3_emb_dim = 256, # stage 3 (same as above)
s3_patch_size = 2,
s3_local_patch_size = 7,
s3_global_k = 7,
s3_depth = 5,
s4_emb_dim = 512, # stage 4 (same as above)
s4_patch_size = 2,
s4_local_patch_size = 7,
s4_global_k = 7,
s4_depth = 4,
peg_kernel_size = 3, # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
```
## RegionViT
This paper proposes mixing local and global attention, along with position encoding generator (proposed in CPVT) and global average pooling, to achieve the same results as Swin, without the extra complexity of shifted windows, CLS tokens, nor positional embeddings.
```python
import torch
from vit_pytorch.twins_svt import TwinsSVT
model = TwinsSVT(
num_classes = 1000, # number of output classes
s1_emb_dim = ***, # stage 1 - patch embedding projected dimension
s1_patch_size = 4, # stage 1 - patch size for patch embedding
s1_local_patch_size = 7, # stage 1 - patch size for local attention
s1_global_k = 7, # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1, # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128, # stage 2 (same as above)
s2_patch_size = 2,
s2_local_patch_size = 7,
s2_global_k = 7,
s2_depth = 1,
s3_emb_dim = 256, # stage 3 (same as above)
s3_patch_size = 2,
s3_local_patch_size = 7,
s3_global_k = 7,
s3_depth = 5,
s4_emb_dim = 512, # stage 4 (same as above)
s4_patch_size = 2,
s4_local_patch_size = 7,
s4_global_k = 7,
s4_depth = 4,
peg_kernel_size = 3, # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
```
## RegionViT

 This paper proposes to divide up the feature map into local regions, whereby the local tokens attend to each other. Each local region has its own regional token which then attends to all its local tokens, as well as other regional tokens.
You can use it as follows
```python
import torch
from vit_pytorch.regionvit import RegionViT
model = RegionViT(
dim = (***, 128, 256, 512), # tuple of size 4, indicating dimension at each stage
depth = (2, 2, 8, 2), # depth of the region to local transformer at each stage
window_size = 7, # window size, which should be either 7 or 14
num_classes = 1000, # number of output classes
tokenize_local_3_conv = False, # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False, # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
```
## CrossFormer
This paper proposes to divide up the feature map into local regions, whereby the local tokens attend to each other. Each local region has its own regional token which then attends to all its local tokens, as well as other regional tokens.
You can use it as follows
```python
import torch
from vit_pytorch.regionvit import RegionViT
model = RegionViT(
dim = (***, 128, 256, 512), # tuple of size 4, indicating dimension at each stage
depth = (2, 2, 8, 2), # depth of the region to local transformer at each stage
window_size = 7, # window size, which should be either 7 or 14
num_classes = 1000, # number of output classes
tokenize_local_3_conv = False, # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False, # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
```
## CrossFormer

 This paper beats PVT and Swin using alternating local and global attention. The global attention is done across the windowing dimension for reduced complexity, much like the scheme used for axial attention.
They also have cross-scale embedding layer, which they shown to be a generic layer that can improve all vision transformers. Dynamic relative positional bias was also formulated to allow the net to generalize to images of greater resolution.
```python
import torch
from vit_pytorch.crossformer import CrossFormer
model = CrossFormer(
num_classes = 1000, # number of output classes
dim = (***, 128, 256, 512), # dimension at each stage
depth = (2, 2, 8, 2), # depth of transformer at each stage
global_window_size = (8, 4, 2, 1), # global window sizes at each stage
local_window_size = 7, # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
```
## ScalableViT
This paper beats PVT and Swin using alternating local and global attention. The global attention is done across the windowing dimension for reduced complexity, much like the scheme used for axial attention.
They also have cross-scale embedding layer, which they shown to be a generic layer that can improve all vision transformers. Dynamic relative positional bias was also formulated to allow the net to generalize to images of greater resolution.
```python
import torch
from vit_pytorch.crossformer import CrossFormer
model = CrossFormer(
num_classes = 1000, # number of output classes
dim = (***, 128, 256, 512), # dimension at each stage
depth = (2, 2, 8, 2), # depth of transformer at each stage
global_window_size = (8, 4, 2, 1), # global window sizes at each stage
local_window_size = 7, # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
```
## ScalableViT

 This Bytedance AI paper proposes the Scalable Self Attention (SSA) and the Interactive Windowed Self Attention (IWSA) modules. The SSA alleviates the computation needed at earlier stages by reducing the key / value feature map by some f ... ...
This Bytedance AI paper proposes the Scalable Self Attention (SSA) and the Interactive Windowed Self Attention (IWSA) modules. The SSA alleviates the computation needed at earlier stages by reducing the key / value feature map by some f ... ... 近期下载者:
相关文件:
收藏者: