ludwig
说明: ludwig,以数据为中心的声明式深度学习框架
(ludwig,Data-centric declarative deep learning framework)
(ludwig,Data-centric declarative deep learning framework)
文件列表:
.actrc (37, 2023-05-18)
.deepsource.toml (118, 2023-05-18)
.devcontainer (0, 2023-05-18)
.devcontainer\Dockerfile (1008, 2023-05-18)
.devcontainer\devcontainer.json (522, 2023-05-18)
.nojekyll (0, 2023-05-18)
.pre-commit-config.yaml (1856, 2023-05-18)
.protolint.yaml (1555, 2023-05-18)
.vscode (0, 2023-05-18)
.vscode\settings.json (407, 2023-05-18)
CODE_OF_CONDUCT.md (123, 2023-05-18)
CONTRIBUTING.md (3201, 2023-05-18)
LICENSE (13489, 2023-05-18)
MANIFEST.in (159, 2023-05-18)
NOTICE (2617, 2023-05-18)
RELEASES.md (747, 2023-05-18)
docker (0, 2023-05-18)
docker\ludwig-gpu (0, 2023-05-18)
docker\ludwig-gpu\Dockerfile (1315, 2023-05-18)
docker\ludwig-ray-gpu (0, 2023-05-18)
docker\ludwig-ray-gpu\Dockerfile (1753, 2023-05-18)
docker\ludwig-ray (0, 2023-05-18)
docker\ludwig-ray\Dockerfile (961, 2023-05-18)
... ...
.deepsource.toml (118, 2023-05-18)
.devcontainer (0, 2023-05-18)
.devcontainer\Dockerfile (1008, 2023-05-18)
.devcontainer\devcontainer.json (522, 2023-05-18)
.nojekyll (0, 2023-05-18)
.pre-commit-config.yaml (1856, 2023-05-18)
.protolint.yaml (1555, 2023-05-18)
.vscode (0, 2023-05-18)
.vscode\settings.json (407, 2023-05-18)
CODE_OF_CONDUCT.md (123, 2023-05-18)
CONTRIBUTING.md (3201, 2023-05-18)
LICENSE (13489, 2023-05-18)
MANIFEST.in (159, 2023-05-18)
NOTICE (2617, 2023-05-18)
RELEASES.md (747, 2023-05-18)
docker (0, 2023-05-18)
docker\ludwig-gpu (0, 2023-05-18)
docker\ludwig-gpu\Dockerfile (1315, 2023-05-18)
docker\ludwig-ray-gpu (0, 2023-05-18)
docker\ludwig-ray-gpu\Dockerfile (1753, 2023-05-18)
docker\ludwig-ray (0, 2023-05-18)
docker\ludwig-ray\Dockerfile (961, 2023-05-18)
... ...


# Getting Involved - [Slack](https://join.slack.com/t/ludwig-ai/shared_invite/zt-mrxo87w6-DlX5~73T2B4v_g6jj0pJcQ) - [Twitter](https://twitter.com/ludwig_ai) - [Medium](https://medium.com/ludwig-ai) - [GitHub Issues](https://github.com/ludwig-ai/ludwig/issues)
[](https://badge.fury.io/py/ludwig)
[](https://img.shields.io/github/commit-activity/m/ludwig-ai/ludwig)
[](https://bestpractices.coreinfrastructure.org/projects/4210)
[](https://join.slack.com/t/ludwig-ai/shared_invite/zt-mrxo87w6-DlX5~73T2B4v_g6jj0pJcQ)
[](https://hub.docker.com/r/ludwigai)
[](https://pepy.tech/project/ludwig)
[](https://github.com/ludwig-ai/ludwig/blob/master/LICENSE)
[](https://twitter.com/ludwig_ai)
Full Documentation: [ludwig.ai](https://ludwig.ai)
# What is Ludwig?
Ludwig is a [declarative machine learning framework](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/what_is_ludwig/#why-declarative-machine-learning-systems)
that makes it easy to define machine learning pipelines using a simple and
flexible data-driven configuration system. Ludwig is suitable for a wide variety
of AI tasks, and is hosted by the
[Linux Foundation AI & Data](https://lfaidata.foundation/).
The configuration declares the input and output features, with their respective
data types. Users can also specify additional parameters to preprocess, encode,
and decode features, load from pre-trained models, compose the internal model
architecture, set training parameters, or run hyperparameter optimization.
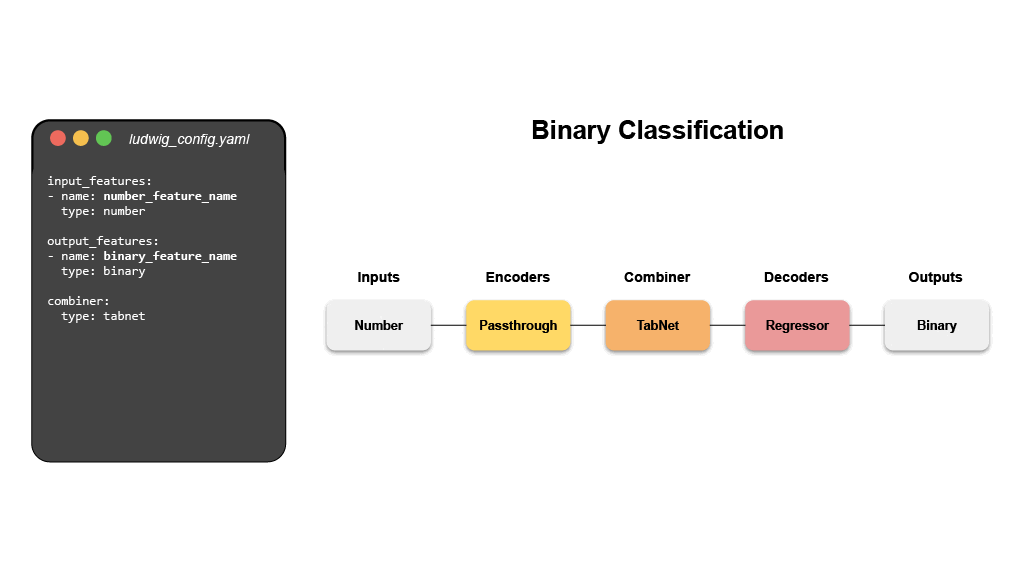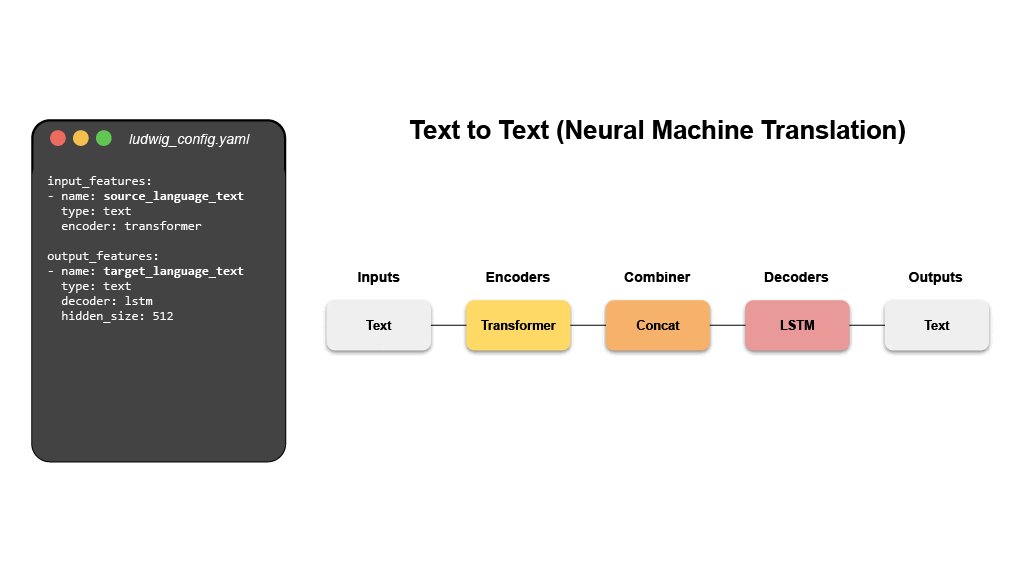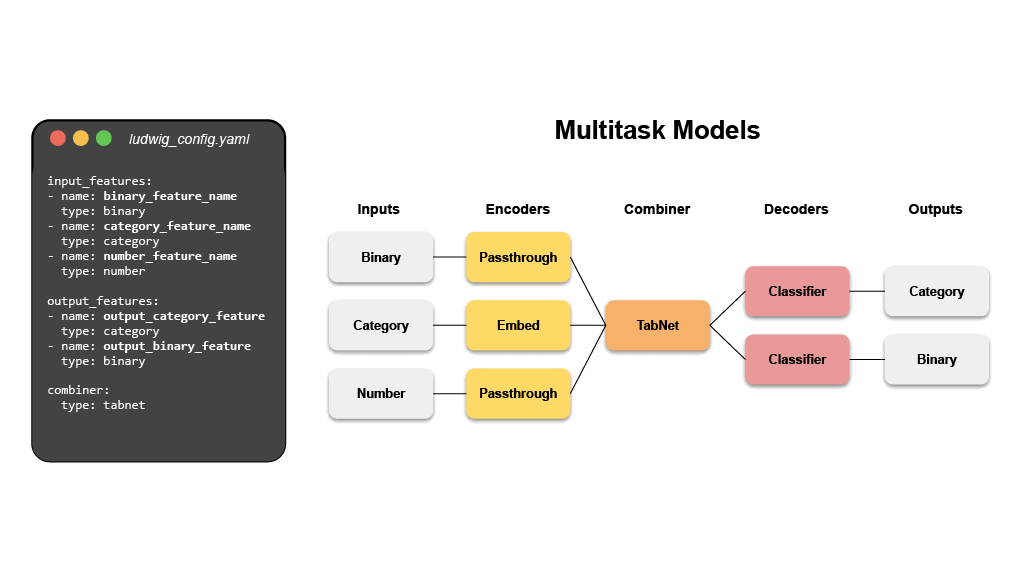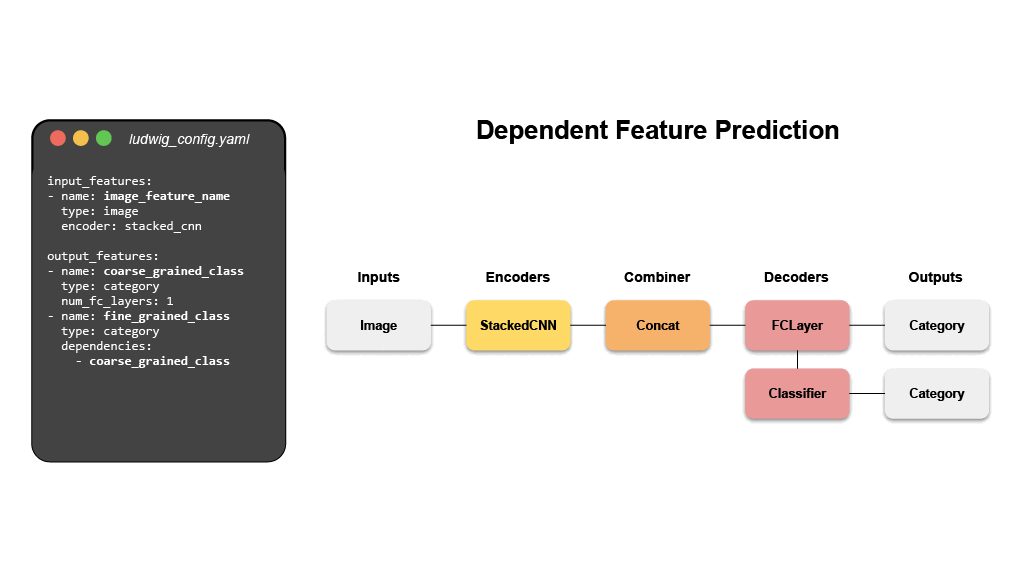
Ludwig will build an end-to-end machine learning pipeline automatically, using
whatever is explicitly specified in the configuration, while falling back to
smart defaults for any parameters that are not.
# Declarative Machine Learning
Ludwig’s declarative approach to machine learning empowers you to have full
control of the components of the machine learning pipeline that you care about,
while leaving it up to Ludwig to make reasonable decisions for the rest.

Analysts, scientists, engineers, and researchers use Ludwig to explore
state-of-the-art model architectures, run hyperparameter search, scale up to
larger than available memory datasets and multi-node clusters, and finally
serve the best model in production.
Finally, the use of abstract interfaces throughout the codebase makes it easy
for users to extend Ludwig by adding new models, metrics, losses, and
preprocessing functions that can be registered to make them immediately useable
in the same unified configuration system.
# Main Features
- **[Data-Driven configuration system](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/how_ludwig_works)**
A config YAML file that describes the schema of your data (input features,
output features, and their types) is all you need to start training deep
learning models. Ludwig uses declared features to compose a deep learning
model accordingly.
```yaml
input_features:
- name: data_column_1
type: number
- name: data_column_2
type: category
- name: data_column_3
type: text
- name: data_column_4
type: image
...
output_features:
- name: data_column_5
type: number
- name: data_column_6
type: category
...
```
- **[Training, prediction, and evaluation from the command line](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/command_line_interface)**
Simple commands can be used to train models and predict new data.
```shell
ludwig train --config config.yaml --dataset data.csv
ludwig predict --model_path results/experiment_run/model --dataset test.csv
ludwig eval --model_path results/experiment_run/model --dataset test.csv
```
- **[Programmatic API](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/api/LudwigModel)**
Ludwig also provides a simple programmatic API for all of the functionality
described above and more.
```python
from ludwig.api import LudwigModel
# train a model
config = {
"input_features": [...],
"output_features": [...],
}
model = LudwigModel(config)
data = pd.read_csv("data.csv")
train_stats, _, model_dir = model.train(data)
# or load a model
model = LudwigModel.load(model_dir)
# obtain predictions
predictions = model.predict(data)
```
- **[Distributed training](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/distributed_training)**
Train models in a distributed setting
which allows training on a single machine with multiple GPUs or multiple
machines with multiple GPUs.
- **[Serving](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/serving)**
Serve models using FastAPI.
```shell
ludwig serve --model_path ./results/experiment_run/model
curl http://0.0.0.0:8000/predict -X POST -F "movie_title=Friends With Money" -F "content_rating=R" -F "genres=Art House & International, Comedy, Drama" -F "runtime=88.0" -F "top_critic=TRUE" -F "review_content=The cast is terrific, the movie isn't."
```
- **[Hyperparameter optimization](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/hyperopt)**
Run hyperparameter optimization locally or using [Ray Tune](https://docs.ray.io/en/latest/tune/index.html).
```shell
ludwig hyperopt --config config.yaml --dataset data.csv
```
- **[AutoML](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/automl)**
Ludwig AutoML takes a dataset, the target column, and a time budget, and
returns a trained Ludwig model.
- **[Third-Party integrations](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/integrations)**
Ludwig provides an extendable interface to integrate with third-party
systems for tracking experiments. Third-party integrations exist for Comet
ML, Weights & Biases, WhyLabs, and MLFlow.
- **[Extensibility](https://ludwig-ai.github.io/ludwig-docs/latest/developer_guide)**
Ludwig is built from the ground up with extensibility in mind. It is easy to
add new data types by implementing clear, well-documented abstract classes
that define functions to preprocess, encode, and decode data.
Furthermore, new `torch nn.Module` models can be easily added by them to a
registry. This encourages reuse and sharing new models with the community.
Refer to the [Developer Guide](https://ludwig-ai.github.io/ludwig-docs/latest/developer_guide)
for further details.
# Quick Start
For a full tutorial, check out the official [getting started guide](https://ludwig-ai.github.io/ludwig-docs/latest/getting_started/),
or take a look at end-to-end [Examples](https://ludwig-ai.github.io/ludwig-docs/latest/examples).
## Step 1: Install
Install from PyPi. Be aware that Ludwig requires Python 3.8+.
```shell
pip install ludwig
```
## Step 2: Define a configuration
Create a config that describes the schema of your data.
Assume we have a text classification task, with data containing a sentence and class column like the following.
| sentence | class |
| :----------------------------------: | :------: |
| Former president Barack Obama ... | politics |
| Juventus hired Cristiano Ronaldo ... | sport |
| LeBron James joins the Lakers ... | sport |
| ... | ... |
A configuration will look like this.
```yaml
input_features:
- name: sentence
type: text
output_features:
- name: class
type: category
```
Starting from a simple config like the one above, any and all aspects of the model architecture, training loop,
hyperparameter search, and backend infrastructure can be modified as additional fields in the declarative configuration
to customize the pipeline to meet your requirements.
```yaml
input_features:
- name: sentence
type: text
encoder: transformer
layers: 6
embedding_size: 512
output_features:
- name: class
type: category
loss: cross_entropy
trainer:
epochs: 50
batch_size: ***
optimizer:
type: adamw
beat1: 0.9
learning_rate: 0.001
backend:
type: ray
cache_format: parquet
processor:
type: dask
trainer:
use_gpu: true
num_workers: 4
resources_per_worker:
CPU: 4
GPU: 1
hyperopt:
metric: f1
sampler: random
parameters:
title.num_layers:
lower: 1
upper: 5
trainer.learning_rate:
values: [0.01, 0.003, 0.001]
```
For details on what can be configured, check out [Ludwig Configuration](https://ludwig-ai.github.io/ludwig-docs/latest/configuration/)
docs.
## Step 3: Train a model
Simple commands can be used to train models and predict new data.
```shell
ludwig train --config config.yaml --dataset data.csv
```
## Step 4: Predict and evaluate
The training process will produce a model that can be used for evaluating on and obtaining predictions for new data.
```shell
ludwig predict --model path/to/trained/model --dataset heldout.csv
ludwig evaluate --model path/to/trained/model --dataset heldout.csv
```
## Step 5: Visualize
Ludwig provides a suite of visualization tools allows you to analyze models' training and test performance and to
compare them.
```shell
ludwig visualize --visualization compare_performance --test_statistics path/to/test_statistics_model_1.json path/to/test_statistics_model_2.json
```
For the full set of visualization see the [Visualization Guide](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/visualizations).
## Step 6: Happy modeling
Try applying Ludwig to your data. [Reach out](https://join.slack.com/t/ludwig-ai/shared_invite/zt-mrxo87w6-DlX5~73T2B4v_g6jj0pJcQ)
if you have any questions.
# Advantages
- **Minimal machine learning boilerplate**
Ludwig takes care of the engineering complexity of machine learning out of
the box, enabling research scientists to focus on building models at the
highest level of abstraction. Data preprocessing, hyperparameter
optimization, device management, and distributed training for
`torch.nn.Module` models come completely free.
- **Easily build your benchmarks**
Creating a state-of-the-art baseline and comparing it with a new model is a
simple config change.
- **Easily apply new architectures to multiple problems and datasets**
Apply new models across the extensive set of tasks and datasets that Ludwig
supports. Ludwig includes a
[full benchmarking toolkit](https://arxiv.org/abs/2111.04260) accessible to
any user, for running experiments with multiple models across multiple
datasets with just a simple configuration.
- **Highly configurable data preprocessing, modeling, and metrics**
Any and all aspects of the model architecture, training loop, hyperparameter
search, and backend infrastructure can be modified as additional fields in
the declarative configuration to customize the pipeline to meet your
requirements. For details on what can be configured, check out
[Ludwig Configuration](https://ludwig-ai.github.io/ludwig-docs/latest/configuration/)
docs.
- **Multi-modal, multi-task learning out-of-the-box**
Mix and match tabular data, text, images, and even audio into complex model
configurations without writing code.
- **Rich model exporting and tracking**
Automatically track all trials and metrics with tools like Tensorboard,
Comet ML, Weights & Biases, MLFlow, and Aim Stack.
- **Automatically scale training to multi-GPU, multi-node clusters**
Go from training on your local machine to the cloud without code changes.
- **Low-code interface for state-of-the-art models, including pre-trained Huggingface Transformers**
Ludwig also natively integrates with pre-trained models, such as the ones
available in [Huggingface Transformers](https://huggingface.co/docs/transformers/index).
Users can choose from a vast collection of state-of-the-art pre-trained
PyTorch models to use without needing to write any code at all. For example,
training a BERT-based sentiment analysis model with Ludwig is as simple as:
```shell
ludwig train --dataset sst5 --config_str “{input_features: [{name: sentence, type: text, encoder: bert}], output_features: [{name: label, type: category}]}”
```
- **Low-code interface for AutoML**
[Ludwig AutoML](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/automl/)
allows users to obtain trained models by providing just a dataset, the
target column, and a time budget.
```python
auto_train_results = ludwig.automl.auto_train(dataset=my_dataset_df, target=target_column_name, time_limit_s=7200)
```
- **Easy productionisation**
Ludwig makes it easy to serve deep learning models, including on GPUs.
Launch a REST API for your trained Ludwig model.
```shell
ludwig serve --model_path=/path/to/model
```
Ludwig supports exporting models to efficient Torchscript bundles.
```shell
ludwig export_torchscript -–model_path=/path/to/model
```
# Tutorials
- [Text Classification](https://ludwig-ai.github.io/ludwig-docs/latest/examples/text_classification)
- [Tabular Data Classification](https://ludwig-ai.github.io/ludwig-docs/latest/examples/adult_census_income)
- [Image Classification](https://ludwig-ai.github.io/ludwig-docs/latest/examples/mnist)
- [Multimodal Classification](https://ludwig-ai.github.io/ludwig-docs/latest/examples/multimodal_classification)
# Example Use Cases
- [Named Entity Recognition Tagging](https://ludwig-ai.github.io/ludwig-docs/latest/examples/ner_tagging)
- [Natural Language Understanding](https://ludwig-ai.github.io/ludwig-docs/latest/examples/nlu)
- [Machine Translation](https://ludwig-ai.github.io/ludwig-docs/latest/examples/machine_translation)
- [Chit-Chat Dialogue Modeling through seq2seq](https://ludwig-ai.github.io/ludwig-docs/latest/examples/seq2seq)
- [Sentiment Analysis](https://ludwig-ai.github.io/ludwig-docs/latest/examples/sentiment_analysis)
- [One-shot Learning with Siamese Networks](https://ludwig-ai.github.io/ludwig-docs/latest/examples/oneshot)
- [Visual Question Answering](https://ludwig-ai.github.io/ludwig-docs/latest/examples/visual_qa)
- [Spoken Digit Speech Recognition](https://ludwig-ai.github.io/ludwig-docs/latest/examples/speech_recognition)
- [Speaker Verification](https://ludwig-ai.github.io/ludwig-docs/latest/examples/speaker_verification)
- [Binary Classification (Titanic)](https://ludwig-ai.github.io/ludwig-docs/latest/examples/titanic)
- [Timeseries forecasting](https://ludwig-ai.github.io/ludwig-docs/latest/examples/forecasting)
- [Timeseries forecasting (Weather)](https://ludwig-ai.github.io/ludwig-docs/latest/examples/weather)
- [Movie rating prediction](https://ludwig-ai.github.io/ludwig-docs/latest/examples/movie_ratings)
- [Multi-label classification](https://ludwig-ai.github.io/ludwig-docs/latest/examples/multi_label)
- [Multi-Task Learning](https://ludwig-ai.github.io/ludwig-docs/latest/examples/multi_task)
- [Simple Regression: Fuel Efficiency Prediction](https://ludwig-ai.github.io/ludwig-docs/latest/examples/fuel_efficiency)
- [Fraud Detection](https://ludwig-ai.github.io/ludwig-docs/latest/examples/fraud)
# More Information
Read our publications on [Ludwig](https://arxiv.org/pdf/1909.07930.pdf), [declarative ML](https://arxiv.org/pdf/2107.08148.pdf), and [Ludwig’s SoTA benchmarks](https://openreview.net/pdf?id=hwjnu6qW7E4).
Learn more about [how Ludwig works](https://ludwig-ai.github.io/ludwig-docs/latest/user_guide/how_ludwig_works/), [how to get started](https://ludwig-ai.github.io/ludwig-docs/latest/getting_started/), and work through more [examples](https://ludwig-ai.github.io/ludwig-docs/latest/examples).
If you are interested in contributing, have questions, comments, or thoughts to share, or if you just want to be in the
know, please consider [joining the Ludwig Slack](https://join.slack.com/t/ludwig-ai/shared_invite/zt-mrxo87w6-DlX5~73T2B4v_g6jj0pJcQ) and follow us on [Twitter](https://twitter.com/ludwig_ai)!
# Join the community to build Ludwig with us
Ludwig is an actively managed open-source project that relies on contributions from folks just like
you. Consider joining the active group of Ludwig contributors to make Ludwig an even
more accessible and feature rich framework for everyone to use!
# Getting Involved - [Slack](https://join.slack.com/t/ludwig-ai/shared_invite/zt-mrxo87w6-DlX5~73T2B4v_g6jj0pJcQ) - [Twitter](https://twitter.com/ludwig_ai) - [Medium](https://medium.com/ludwig-ai) - [GitHub Issues](https://github.com/ludwig-ai/ludwig/issues)
近期下载者:
相关文件:
收藏者: