Flink_Music_Album_Data_Analysis
说明: 大数据课程期末考试
(The final exam of Big Data Course)
(The final exam of Big Data Course)
文件列表:
.idea (0, 2021-06-15)
.idea\Flink_Music_Album_Data_Analysis.iml (398, 2021-06-15)
.idea\deployment.xml (1745, 2021-06-15)
.idea\inspectionProfiles (0, 2021-06-15)
.idea\inspectionProfiles\Project_Default.xml (444, 2021-06-15)
.idea\inspectionProfiles\profiles_settings.xml (174, 2021-06-15)
.idea\misc.xml (369, 2021-06-15)
.idea\modules.xml (314, 2021-06-15)
.idea\remote-mappings.xml (519, 2021-06-15)
.idea\vcs.xml (180, 2021-06-15)
.idea\webServers.xml (635, 2021-06-15)
PyFlinkFlask.py (447, 2021-06-15)
main.py (2338, 2021-06-15)
static (0, 2021-06-15)
static\data (0, 2021-06-15)
static\data\album_sales.json (925, 2021-06-15)
static\data\genre.json (724, 2021-06-15)
static\data\top_50_albums.json (1640, 2021-06-15)
static\data\top_5_genres_avg_scores.json (174, 2021-06-15)
static\data\top_5_genres_year_sales.json (2830, 2021-06-15)
static\data\year_albums_and_tracks.json (415, 2021-06-15)
static\js (0, 2021-06-15)
static\js\echarts.min.js (777872, 2021-06-15)
static\js\jquery.min.js (88145, 2021-06-15)
templates (0, 2021-06-15)
templates\album_sales.html (3167, 2021-06-15)
templates\genre.html (3052, 2021-06-15)
templates\index.html (1102, 2021-06-15)
templates\top_50_albums.html (1160, 2021-06-15)
templates\top_5_genres_avg_scores.html (7804, 2021-06-15)
templates\top_5_genres_year_sales.html (4230, 2021-06-15)
templates\word_cloud.jpg (25947, 2021-06-15)
templates\year_albums_and_tracks.html (3136, 2021-06-15)
utils (0, 2021-06-15)
utils\__init__.py (83, 2021-06-15)
utils\albums_to_wordcloud.py (290, 2021-06-15)
utils\statisitic_and_analysis.py (4883, 2021-06-15)
... ...
.idea\Flink_Music_Album_Data_Analysis.iml (398, 2021-06-15)
.idea\deployment.xml (1745, 2021-06-15)
.idea\inspectionProfiles (0, 2021-06-15)
.idea\inspectionProfiles\Project_Default.xml (444, 2021-06-15)
.idea\inspectionProfiles\profiles_settings.xml (174, 2021-06-15)
.idea\misc.xml (369, 2021-06-15)
.idea\modules.xml (314, 2021-06-15)
.idea\remote-mappings.xml (519, 2021-06-15)
.idea\vcs.xml (180, 2021-06-15)
.idea\webServers.xml (635, 2021-06-15)
PyFlinkFlask.py (447, 2021-06-15)
main.py (2338, 2021-06-15)
static (0, 2021-06-15)
static\data (0, 2021-06-15)
static\data\album_sales.json (925, 2021-06-15)
static\data\genre.json (724, 2021-06-15)
static\data\top_50_albums.json (1640, 2021-06-15)
static\data\top_5_genres_avg_scores.json (174, 2021-06-15)
static\data\top_5_genres_year_sales.json (2830, 2021-06-15)
static\data\year_albums_and_tracks.json (415, 2021-06-15)
static\js (0, 2021-06-15)
static\js\echarts.min.js (777872, 2021-06-15)
static\js\jquery.min.js (88145, 2021-06-15)
templates (0, 2021-06-15)
templates\album_sales.html (3167, 2021-06-15)
templates\genre.html (3052, 2021-06-15)
templates\index.html (1102, 2021-06-15)
templates\top_50_albums.html (1160, 2021-06-15)
templates\top_5_genres_avg_scores.html (7804, 2021-06-15)
templates\top_5_genres_year_sales.html (4230, 2021-06-15)
templates\word_cloud.jpg (25947, 2021-06-15)
templates\year_albums_and_tracks.html (3136, 2021-06-15)
utils (0, 2021-06-15)
utils\__init__.py (83, 2021-06-15)
utils\albums_to_wordcloud.py (290, 2021-06-15)
utils\statisitic_and_analysis.py (4883, 2021-06-15)
... ...
# Flink_Music_Album_Data_Analysis
The final exam of Big Data Course
# 一、环境搭建
假设目前的环境是裸机。
1. **安装Linux操作系统**:比如可以安装Ubuntu16.04,可以参考这篇博客,完成操作系统的安装。
2. **安装Hadoop 3.1.4**:需要在Ubuntu16.04系统上安装Hadoop 3.1.4,可以参考这篇博客,完成Hadoop的安装。
3. **安装pyflink 1.13.1**:需要在Ubuntu16.04系统上安装pyflink 1.13.1,可以参考这篇博客或使用如下命令,完成pyflink1.13.1的安装。 ```shell pip install apache-flink==1.13.1 ``` 在上手之前,先大致介绍一下 PyFlink: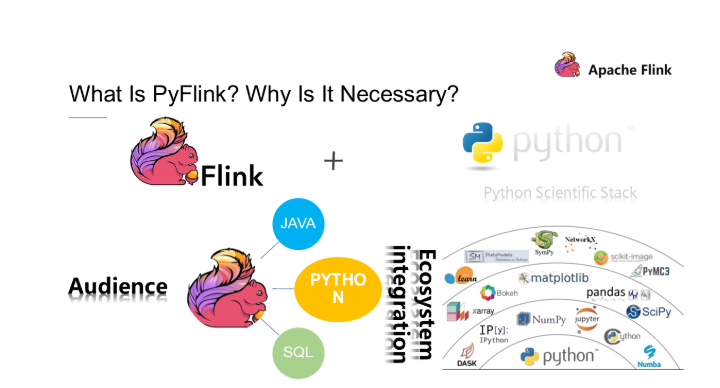 如上图所示。
(1) PyFlink 是 Flink 对 Java API 的一层封装,运行时会启动 JVM 来与 Python 进行通信。
(2) PyFlink 提供了多种不同层级的 API,层级越高封装程度越高(建议在 SQL API 或 Table API 进行编程),层级由高到低分别为:
**1) SQL API**
**2) Table API**
**3) DataStream API / DataSet API**
**4) Stateful Streaming Processing**
如上图所示。
(1) PyFlink 是 Flink 对 Java API 的一层封装,运行时会启动 JVM 来与 Python 进行通信。
(2) PyFlink 提供了多种不同层级的 API,层级越高封装程度越高(建议在 SQL API 或 Table API 进行编程),层级由高到低分别为:
**1) SQL API**
**2) Table API**
**3) DataStream API / DataSet API**
**4) Stateful Streaming Processing**
4. **开发工具:Pycharm**。安装Pycharm 2020.2专业破解版,点击这里查看破解教程。并且配置远程连接服务器,点击这里查看教程。 5. **Python版本:3.7**。在E盘中新建Flink_Music_Album_Data_Analysis文件夹,用PyCharm将其打开并新建static文件夹,再在static文件夹中新建js和data两个文件夹,如下所示。 6. **可视化工具:Echarts**。安装jQuery和Echarts:点击这里下载jQuery,将其另存为jquery.min.js文件,保存在static/js目录下。点击这里下载Echarts,将其另存为echarts.min.js文件,保存在static/js目录下。
到此为止,完成整个实验环境的搭建。
# 二、实验数据集
## 1. 数据集的说明
本次实验使用的数据集来自知名数据网站 Kaggle 的 music-label-dataset数据集,其中包含了10万条音乐专辑和歌手相关的数据。本次实验使用数据集中有关专辑的数据表 albums.csv 进行实验。你可以点击这里下载相关数据集。数据主要包含以下字段:
| 字段名称 | 解释 | 例子 |
| :------------------: | :-------------------------: | :---------------------------------: |
| id | 数据标号 | 1 |
| artist_id | 专辑对应歌手标号 | 1767 |
| album_title | 专辑名称 | Call me Cat Moneyless That Doggies |
| genre | 专辑风格 | Folk |
| year_of_pub | 专辑发行年份 | 2006 |
| num_of_tracks | 专辑中单曲数量 | 11 |
| num_of_sales | 专辑销量 | 905193 |
| rolling_stone_critic | 滚石网站的评分 | 4 |
| mtv_critic | 全球最大音乐电视网MTV的评分 | 1.5 |
| music_maniac_critic | 音乐达人的评分 | 3 |
6. **可视化工具:Echarts**。安装jQuery和Echarts:点击这里下载jQuery,将其另存为jquery.min.js文件,保存在static/js目录下。点击这里下载Echarts,将其另存为echarts.min.js文件,保存在static/js目录下。
到此为止,完成整个实验环境的搭建。
# 二、实验数据集
## 1. 数据集的说明
本次实验使用的数据集来自知名数据网站 Kaggle 的 music-label-dataset数据集,其中包含了10万条音乐专辑和歌手相关的数据。本次实验使用数据集中有关专辑的数据表 albums.csv 进行实验。你可以点击这里下载相关数据集。数据主要包含以下字段:
| 字段名称 | 解释 | 例子 |
| :------------------: | :-------------------------: | :---------------------------------: |
| id | 数据标号 | 1 |
| artist_id | 专辑对应歌手标号 | 1767 |
| album_title | 专辑名称 | Call me Cat Moneyless That Doggies |
| genre | 专辑风格 | Folk |
| year_of_pub | 专辑发行年份 | 2006 |
| num_of_tracks | 专辑中单曲数量 | 11 |
| num_of_sales | 专辑销量 | 905193 |
| rolling_stone_critic | 滚石网站的评分 | 4 |
| mtv_critic | 全球最大音乐电视网MTV的评分 | 1.5 |
| music_maniac_critic | 音乐达人的评分 | 3 |
## 2. 将数据集上传到分布式系统HDFS中 A. 为启动Hadoop中的HDFS组件,在Linux命令行窗口运行如下命令: ```shell $ /usr/local/hadoop/sbin/start-dfs.sh ``` B. 在服务器上创建Albums_data目录存放数据,在命令行运行下面命令: ```shell $ hdfs dfs -mkdir -p /home2/zgx/data/Albums_data ``` C. 把本地文件系统中的数据集albums.csv上传到分布式文件系统HDFS,在命令行运行下面命令: ```shell $ hdfs dfs -put albums.csv ``` 上传成功的结果图如下。 # 三、数据预处理
## 1. 建立工程文件
A. 在项目中创建main.py文件。
B. 在项目中创建templates文件夹,用于存放展示数据分析结果的html文件。
C. 创建文件夹名为utils的python工具包,并且创建statisitic_and_analysis.py和albums_to_wordcloud.py用于存放数据分析函数,同时在__ init __.py中添加如下代码,
```python
from utils.statisitic_and_analysis import *
from utils.albums_to_wordcloud import *
```
该代码能让数据分析函数直接被main.py调用。
D. 在项目中创建PyFlinkFlask.py文件。该文件存放Flask应用。用于调用Echarts实现界面展示。
实现后代码的结果如下所示。
# 三、数据预处理
## 1. 建立工程文件
A. 在项目中创建main.py文件。
B. 在项目中创建templates文件夹,用于存放展示数据分析结果的html文件。
C. 创建文件夹名为utils的python工具包,并且创建statisitic_and_analysis.py和albums_to_wordcloud.py用于存放数据分析函数,同时在__ init __.py中添加如下代码,
```python
from utils.statisitic_and_analysis import *
from utils.albums_to_wordcloud import *
```
该代码能让数据分析函数直接被main.py调用。
D. 在项目中创建PyFlinkFlask.py文件。该文件存放Flask应用。用于调用Echarts实现界面展示。
实现后代码的结果如下所示。
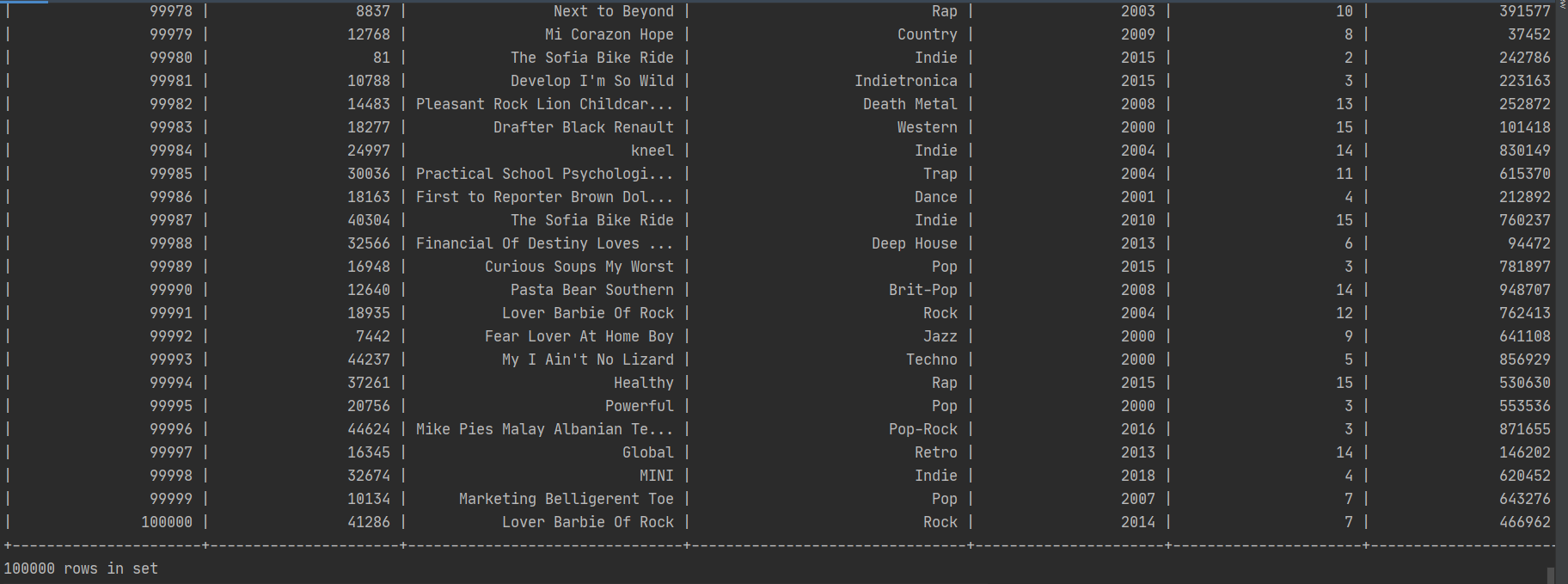
 ## 2. 使用Flink将数据转为Table对象
由于读入的文件是csv文件,是结构化的数据。所以可以用pandas对象先读入csv文件,再调用PyFlink的Table API可以将pandas的DataFrame对象转化为Table对象进行分析。核心代码如下所示。
```python
pdf = pd.read_csv(data_dir + 'albums.csv')
table = t_env.from_pandas(pdf)
```
PyFlink1.14的API参考可以点击这里。调用from_pandas方法的好处在于可以将csv的所有列都读入一个临时表中,这样避免了使用CsvTable类去逐个调用每一列去组成一个临时表的繁琐操作,转为后的table打印出来的结果如下。
## 2. 使用Flink将数据转为Table对象
由于读入的文件是csv文件,是结构化的数据。所以可以用pandas对象先读入csv文件,再调用PyFlink的Table API可以将pandas的DataFrame对象转化为Table对象进行分析。核心代码如下所示。
```python
pdf = pd.read_csv(data_dir + 'albums.csv')
table = t_env.from_pandas(pdf)
```
PyFlink1.14的API参考可以点击这里。调用from_pandas方法的好处在于可以将csv的所有列都读入一个临时表中,这样避免了使用CsvTable类去逐个调用每一列去组成一个临时表的繁琐操作,转为后的table打印出来的结果如下。
 下面main.py中的代码段完成了文件从csv到pandas的DataFrame对象,再到Flink的Table对象的转化。
```python
from pyflink.table import EnvironmentSettings, TableEnvironment
import pandas as pd
if __name__ == "__main__":
# 1. 设置用于批处理的初始环境属性
settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()
t_env = TableEnvironment.create(settings)
# 设置处理数据的并行度
t_env.get_config().get_configuration().set_string("parallelism.default", "1")
# 设置读入数据的路径
data_dir = '/home2/zgx/data/Albums_data/'
# 2. 读入csv文件转为pandas的DataFrame对象
pdf = pd.read_csv(data_dir + 'albums.csv')
# 3. 将DataFrame对象转化为Flink的Table的对象
table = t_env.from_pandas(pdf)
# 将table对象进行处理并打印出来
table.execute().print()
```
至此,完成csv文件到Flink的Table对象的转换。
# 四、数据分析
本实验的数据分析代码放在主目录中的utils包的statisitic_and_analysis.py中,主要实现以下六个数据分析统计函数。
1. 2000年~2019年各类型专辑的数量的统计;
2. 2000年-2019年最受欢迎的50张专辑的词云图;
3. 2000年-2019年各类型专辑销量的统计;
4. 2000年-2019年每年的专辑数量和单曲数量的统计;
5. 2000年-2019年总销量前五的专辑类型的各年份销量的统计;
6. 2000年-2019年总销量前五的专辑类型在各个评价网站上平均分数的统计。
为了方便数据可视化,对于每个不同的分析,都将分析结果导出json文件由web页面读取并且进行可视化操作。
以下将详细介绍utils包中的6个数据分析函数。
## 1. 2000年~2019年各类型专辑的数量的统计
为了统计统计20年间各类风格的音乐专辑的总数量,复制以下代码到statisitic_and_analysis.py。
```python
from pyflink.table.expressions import lit, col
import json
# 第1个图:统计20年间各类风格的音乐专辑的总数量
def genre(table, json_save_dir, file_name):
table_results = table.group_by(col("genre")).select(col("genre"), lit(1).count.alias("genre_num")).execute()
# table_results.print()
res = []
with table_results.collect() as results:
for result in results:
res.append(result.__dict__.get('_values'))
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(res))
f.close()
```
上述函数利用Flink中的Table API提取出不同风格的专辑出现的次数,最后的结果保存于json中。函数返回的数据格式是
```json
[["Folk", 1912], ["Metal", 1934],...,]
```
## 2. 2000年-2019年最受欢迎的50张专辑的词云图
为了统计20年间最受欢迎的50张专辑,复制以下代码到statisitic_and_analysis.py。
```python
# 第2个图:统计20年间销量在前50的音乐专辑名称并用词云显示
def top_50_albums(table, json_save_dir, file_name):
table_results = table.select(col("album_title"), col("num_of_sales")).order_by(
col("num_of_sales").desc).limit(50).execute()
ans = {}
with table_results.collect() as results:
for result in results:
ans[result.__dict__.get('_values')[0]] = result.__dict__.get('_values')[1] - 999000
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
为了生成词云图,复制以下代码到albums_to_wordcloud.py。
```python
from wordcloud import WordCloud
import json
def analysis_top_50_albums():
data1 = json.load(open('../static/data/top_50_albums.json'))
wc1 = WordCloud(background_color='white',
).generate_from_frequencies(data1)
wc1.to_file("../templates/word_cloud.jpg")
```
为实现词云图,先调用table中的order_by()方法将专辑名称按销量降序排列,再用limit()方法统计出销量前50的专辑名称。最后使用python中的WordCloud库实现词云的生成。
## 3. 2000年-2019年各类型专辑销量的统计
为了统计20年间各类型专辑的销量,复制以下代码到statisitic_and_analysis.py。
```python
# 第3个图:各类型专辑的销量统计图
def album_sales(table, json_save_dir, file_name):
table_results = table.group_by(col("genre")).select(col("genre"),
col("num_of_sales").sum.alias(
"each_album_genre_sales")).execute()
# table_results.print()
res = []
with table_results.collect() as results:
for result in results:
res.append(result.__dict__.get('_values'))
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(res))
f.close()
```
上述函数利用Flink中的Table API中col的sum方法,将不同年份同一类型专辑的销量进行求和,最后的结果保存于json中。函数返回的数据格式是
```json
[["Folk", 965444874], ["Metal", ***3639223],...]
```
## 4. 2000年-2019年每年的专辑数量和单曲数量的统计
为了统计20年间每年的专辑数量和单曲数量,复制以下代码到statisitic_and_analysis.py。
```python
# 第4个图:统计每年的专辑数量和单曲数量
def year_albums_and_tracks(table, json_save_dir, file_name):
table_results = table.group_by(col("year_of_pub")).select(col("year_of_pub"),
col("genre").count.alias("genres_num"),
col("num_of_tracks").sum.alias("tracks_num")).order_by(
col("year_of_pub").asc).execute()
# table_results.print()
ans = {"tracks": [], "years": [], "albums": []}
with table_results.collect() as results:
for result in results:
# res.append(result.__dict__.get('_values'))
ans["tracks"].append(result.__dict__.get('_values')[2])
ans["years"].append(result.__dict__.get('_values')[0])
ans["albums"].append(result.__dict__.get('_values')[1])
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
上述函数将统计的每年的单曲数、年份、每年专辑类型数存于ans字典中,最后的结果保存于json中。函数返回的数据格式是
```json
{
"tracks": [41816,...],
"years": [2000,...],
"albums": [4921,...]
}
```
## 5. 2000年-2019年总销量前五的专辑类型的各年份销量的统计
为了统计20年间总销量前五的专辑类型的各年份销量,复制以下代码到statisitic_and_analysis.py。
```python
# 返回总销量是前五的专辑类型
def top_5_genres_list(table):
table_results = table.group_by(col("genre")).select(col("genre"),
col("num_of_sales").sum.alias("each_album_sales")).order_by(
col("each_album_sales").desc).limit(5).execute()
list = []
with table_results.collect() as results:
for result in results:
# print(result.__dict__.get('_values')[0])
list.append(result.__dict__.get('_values')[0])
# print(list)
return list
# 第五个图:总销量前五类型的专辑各年份销量
def top_5_genres_years_sales(table, genres_list, json_save_dir, file_name):
ans = {}
for genre in genres_list:
table_results = table.filter(col("genre") == genre).group_by(col("year_of_pub")).select(col("year_of_pub"), col(
"num_of_sales").sum.alias(
"years_of_sales")).order_by(
col("year_of_pub").asc).execute()
list = []
with table_results.collect() as results:
for result in results:
result.__dict__.get('_values').insert(0, genre)
list.append(result.__dict__.get('_values'))
ans[genre] = list
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
上述函数做了两件事情,首先先用函数top_5_genres_list()找到整个数据集中总销量为前五的专辑,再将前五专辑送入函数top_5_genres_years_sales()中,统计各年份的销量。最后的结果保存于json中。函数返回的数据格式是
```json
{
"Indie": [["Indie", 2000, 237517311],...
}
```
## 6. 2000年-2019年总销量前五的专辑类型在各个评价网站上平均分数的统计
为了统计20年间总销量前五的专辑类型在各个评价网站上平均分数,复制以下代码到statisitic_and_analysis.py。
```python
# 第六个图:总销量前五专辑类型在不同评分系统的平均分数
def top_5_genres_avg_scores(table, genres_list, json_save_dir, file_name):
# genres_list = top_5_genres_list(table)
list = []
for genre in genres_list:
table_results = table.filter(col("genre") == genre).select(col("rolling_stone_critic").avg,
col("mtv_critic").avg,
col("music_maniac_critic").avg).execute()
with table_results.collect() as results:
for result in results:
temp = [round(x, 4) for x in result.__dict__.get('_values')]
temp.insert(0, genre)
list.append(temp)
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(list))
f.close()
```
上述函数使用Flink Table API中col的avg函数,将各个网站的评分直接取平均,最后的结果保存于json中。函数返回的数据格式是
```json
[["Indie", 2.7373, 2.7499, 2.7475],
["Pop", 2.7195, 2.7369, 2.7552],...
]
```
# 五、可视化展示
本实验的可视化是基于echarts实现的,实现的可视化页面部署在基于flask框架的web服务器上。
## 1. 建立Flask应用
在PyFlinkFlask.py中复制以下代码:
```python
from flask import render_template
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
# 使用render_template的方法来渲染页面
return render_template('index.html')
@app.route('/
下面main.py中的代码段完成了文件从csv到pandas的DataFrame对象,再到Flink的Table对象的转化。
```python
from pyflink.table import EnvironmentSettings, TableEnvironment
import pandas as pd
if __name__ == "__main__":
# 1. 设置用于批处理的初始环境属性
settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()
t_env = TableEnvironment.create(settings)
# 设置处理数据的并行度
t_env.get_config().get_configuration().set_string("parallelism.default", "1")
# 设置读入数据的路径
data_dir = '/home2/zgx/data/Albums_data/'
# 2. 读入csv文件转为pandas的DataFrame对象
pdf = pd.read_csv(data_dir + 'albums.csv')
# 3. 将DataFrame对象转化为Flink的Table的对象
table = t_env.from_pandas(pdf)
# 将table对象进行处理并打印出来
table.execute().print()
```
至此,完成csv文件到Flink的Table对象的转换。
# 四、数据分析
本实验的数据分析代码放在主目录中的utils包的statisitic_and_analysis.py中,主要实现以下六个数据分析统计函数。
1. 2000年~2019年各类型专辑的数量的统计;
2. 2000年-2019年最受欢迎的50张专辑的词云图;
3. 2000年-2019年各类型专辑销量的统计;
4. 2000年-2019年每年的专辑数量和单曲数量的统计;
5. 2000年-2019年总销量前五的专辑类型的各年份销量的统计;
6. 2000年-2019年总销量前五的专辑类型在各个评价网站上平均分数的统计。
为了方便数据可视化,对于每个不同的分析,都将分析结果导出json文件由web页面读取并且进行可视化操作。
以下将详细介绍utils包中的6个数据分析函数。
## 1. 2000年~2019年各类型专辑的数量的统计
为了统计统计20年间各类风格的音乐专辑的总数量,复制以下代码到statisitic_and_analysis.py。
```python
from pyflink.table.expressions import lit, col
import json
# 第1个图:统计20年间各类风格的音乐专辑的总数量
def genre(table, json_save_dir, file_name):
table_results = table.group_by(col("genre")).select(col("genre"), lit(1).count.alias("genre_num")).execute()
# table_results.print()
res = []
with table_results.collect() as results:
for result in results:
res.append(result.__dict__.get('_values'))
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(res))
f.close()
```
上述函数利用Flink中的Table API提取出不同风格的专辑出现的次数,最后的结果保存于json中。函数返回的数据格式是
```json
[["Folk", 1912], ["Metal", 1934],...,]
```
## 2. 2000年-2019年最受欢迎的50张专辑的词云图
为了统计20年间最受欢迎的50张专辑,复制以下代码到statisitic_and_analysis.py。
```python
# 第2个图:统计20年间销量在前50的音乐专辑名称并用词云显示
def top_50_albums(table, json_save_dir, file_name):
table_results = table.select(col("album_title"), col("num_of_sales")).order_by(
col("num_of_sales").desc).limit(50).execute()
ans = {}
with table_results.collect() as results:
for result in results:
ans[result.__dict__.get('_values')[0]] = result.__dict__.get('_values')[1] - 999000
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
为了生成词云图,复制以下代码到albums_to_wordcloud.py。
```python
from wordcloud import WordCloud
import json
def analysis_top_50_albums():
data1 = json.load(open('../static/data/top_50_albums.json'))
wc1 = WordCloud(background_color='white',
).generate_from_frequencies(data1)
wc1.to_file("../templates/word_cloud.jpg")
```
为实现词云图,先调用table中的order_by()方法将专辑名称按销量降序排列,再用limit()方法统计出销量前50的专辑名称。最后使用python中的WordCloud库实现词云的生成。
## 3. 2000年-2019年各类型专辑销量的统计
为了统计20年间各类型专辑的销量,复制以下代码到statisitic_and_analysis.py。
```python
# 第3个图:各类型专辑的销量统计图
def album_sales(table, json_save_dir, file_name):
table_results = table.group_by(col("genre")).select(col("genre"),
col("num_of_sales").sum.alias(
"each_album_genre_sales")).execute()
# table_results.print()
res = []
with table_results.collect() as results:
for result in results:
res.append(result.__dict__.get('_values'))
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(res))
f.close()
```
上述函数利用Flink中的Table API中col的sum方法,将不同年份同一类型专辑的销量进行求和,最后的结果保存于json中。函数返回的数据格式是
```json
[["Folk", 965444874], ["Metal", ***3639223],...]
```
## 4. 2000年-2019年每年的专辑数量和单曲数量的统计
为了统计20年间每年的专辑数量和单曲数量,复制以下代码到statisitic_and_analysis.py。
```python
# 第4个图:统计每年的专辑数量和单曲数量
def year_albums_and_tracks(table, json_save_dir, file_name):
table_results = table.group_by(col("year_of_pub")).select(col("year_of_pub"),
col("genre").count.alias("genres_num"),
col("num_of_tracks").sum.alias("tracks_num")).order_by(
col("year_of_pub").asc).execute()
# table_results.print()
ans = {"tracks": [], "years": [], "albums": []}
with table_results.collect() as results:
for result in results:
# res.append(result.__dict__.get('_values'))
ans["tracks"].append(result.__dict__.get('_values')[2])
ans["years"].append(result.__dict__.get('_values')[0])
ans["albums"].append(result.__dict__.get('_values')[1])
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
上述函数将统计的每年的单曲数、年份、每年专辑类型数存于ans字典中,最后的结果保存于json中。函数返回的数据格式是
```json
{
"tracks": [41816,...],
"years": [2000,...],
"albums": [4921,...]
}
```
## 5. 2000年-2019年总销量前五的专辑类型的各年份销量的统计
为了统计20年间总销量前五的专辑类型的各年份销量,复制以下代码到statisitic_and_analysis.py。
```python
# 返回总销量是前五的专辑类型
def top_5_genres_list(table):
table_results = table.group_by(col("genre")).select(col("genre"),
col("num_of_sales").sum.alias("each_album_sales")).order_by(
col("each_album_sales").desc).limit(5).execute()
list = []
with table_results.collect() as results:
for result in results:
# print(result.__dict__.get('_values')[0])
list.append(result.__dict__.get('_values')[0])
# print(list)
return list
# 第五个图:总销量前五类型的专辑各年份销量
def top_5_genres_years_sales(table, genres_list, json_save_dir, file_name):
ans = {}
for genre in genres_list:
table_results = table.filter(col("genre") == genre).group_by(col("year_of_pub")).select(col("year_of_pub"), col(
"num_of_sales").sum.alias(
"years_of_sales")).order_by(
col("year_of_pub").asc).execute()
list = []
with table_results.collect() as results:
for result in results:
result.__dict__.get('_values').insert(0, genre)
list.append(result.__dict__.get('_values'))
ans[genre] = list
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
上述函数做了两件事情,首先先用函数top_5_genres_list()找到整个数据集中总销量为前五的专辑,再将前五专辑送入函数top_5_genres_years_sales()中,统计各年份的销量。最后的结果保存于json中。函数返回的数据格式是
```json
{
"Indie": [["Indie", 2000, 237517311],...
}
```
## 6. 2000年-2019年总销量前五的专辑类型在各个评价网站上平均分数的统计
为了统计20年间总销量前五的专辑类型在各个评价网站上平均分数,复制以下代码到statisitic_and_analysis.py。
```python
# 第六个图:总销量前五专辑类型在不同评分系统的平均分数
def top_5_genres_avg_scores(table, genres_list, json_save_dir, file_name):
# genres_list = top_5_genres_list(table)
list = []
for genre in genres_list:
table_results = table.filter(col("genre") == genre).select(col("rolling_stone_critic").avg,
col("mtv_critic").avg,
col("music_maniac_critic").avg).execute()
with table_results.collect() as results:
for result in results:
temp = [round(x, 4) for x in result.__dict__.get('_values')]
temp.insert(0, genre)
list.append(temp)
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(list))
f.close()
```
上述函数使用Flink Table API中col的avg函数,将各个网站的评分直接取平均,最后的结果保存于json中。函数返回的数据格式是
```json
[["Indie", 2.7373, 2.7499, 2.7475],
["Pop", 2.7195, 2.7369, 2.7552],...
]
```
# 五、可视化展示
本实验的可视化是基于echarts实现的,实现的可视化页面部署在基于flask框架的web服务器上。
## 1. 建立Flask应用
在PyFlinkFlask.py中复制以下代码:
```python
from flask import render_template
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
# 使用render_template的方法来渲染页面
return render_template('index.html')
@app.route('/')
def req_file(filename):
return render_template(filename)
if __name__ == "__main__":
# 代码调试生效
app.debug = True
# 模板调试立即生效
app.jinja_env.auto_reload = True
app.run()
```
## 2. Echarts画图
具体前端代码可参考templates目录下的各个html。
## 3. 界面展示和结果分析
在Pycharm的index.html中点击“谷歌浏览器”即可实现本地预览。操作如下图红框所示。
 点击后可以看到如下界面。
点击后可以看到如下界面。
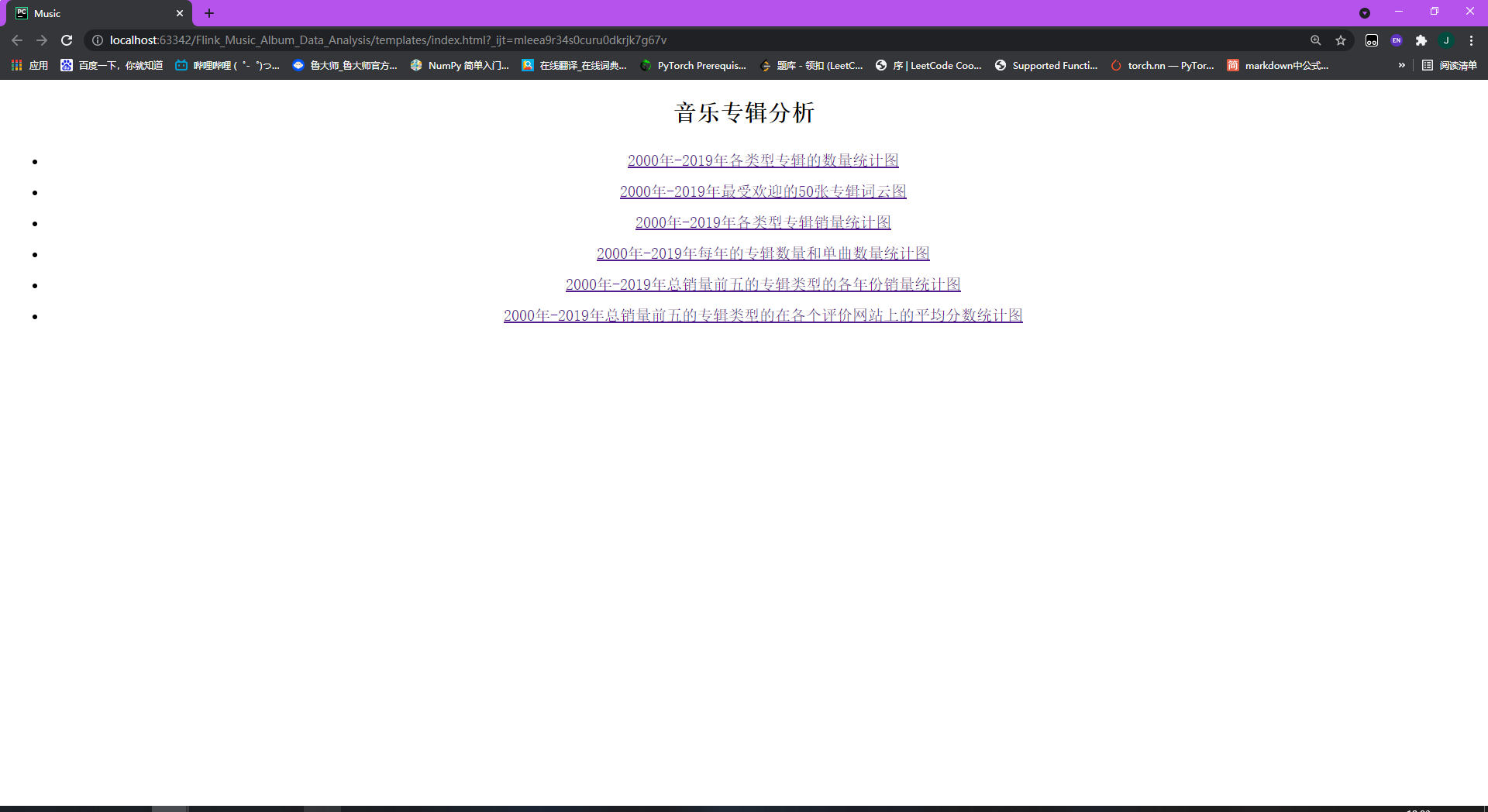 上述是本次实验的各个数据分析统计图的链接。
### (1)2000年-2019年各类型专辑的数量统计图
上述是本次实验的各个数据分析统计图的链接。
### (1)2000年-2019年各类型专辑的数量统计图
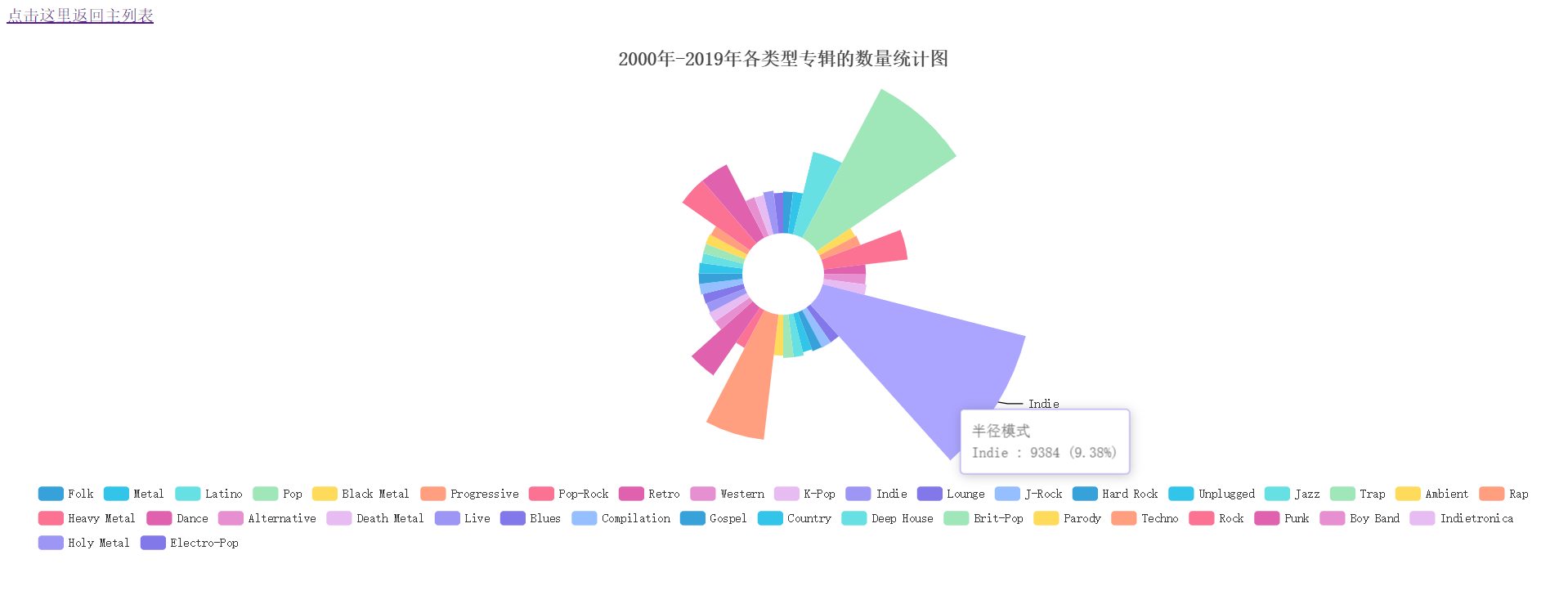 实验结果分析:由玫瑰花图可知,这20年来,比较受欢迎的前8的专辑风格分别是Indie、Pop、Rap、Pop-Rock、Dance、Rock、Punk、Latino。
### (2)2000年-2019年最受欢迎的50张专辑词云图
实验结果分析:由玫瑰花图可知,这20年来,比较受欢迎的前8的专辑风格分别是Indie、Pop、Rap、Pop-Rock、Dance、Rock、Punk、Latino。
### (2)2000年-2019年最受欢迎的50张专辑词云图
 实验结果分析:由词云图可知,这20年来,比较受欢迎的前3专辑是Decent Waterbuck、Little of Pahari、Every Country Toys Chameleon。
### (3)2000年-2019年各类型专辑销量统计图
实验结果分析:由词云图可知,这20年来,比较受欢迎的前3专辑是Decent Waterbuck、Little of Pahari、Every Country Toys Chameleon。
### (3)2000年-2019年各类型专辑销量统计图
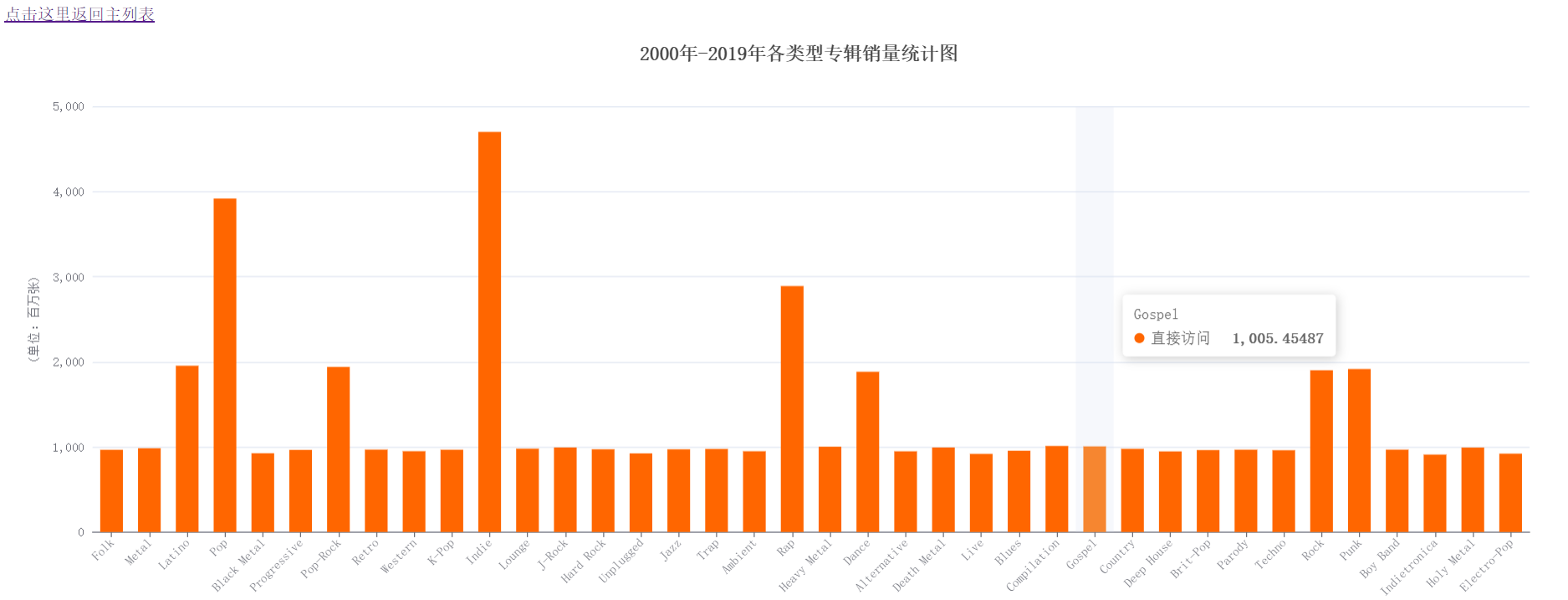 实验结果分析:由柱状图可知,这20年来,比较畅销的前8专辑风格的分别是Indie、Pop、Rap、Dance、Latino、Pop-Rock、Rock、Punk。这种结果与上述玫瑰花图的结果不谋而合,这些类型的专辑比较广为大众认可。所以畅销量较大。
### (4)2000年-2019年每年的专辑数量和单曲数量统计图
实验结果分析:由柱状图可知,这20年来,比较畅销的前8专辑风格的分别是Indie、Pop、Rap、Dance、Latino、Pop-Rock、Rock、Punk。这种结果与上述玫瑰花图的结果不谋而合,这些类型的专辑比较广为大众认可。所以畅销量较大。
### (4)2000年-2019年每年的专辑数量和单曲数量统计图
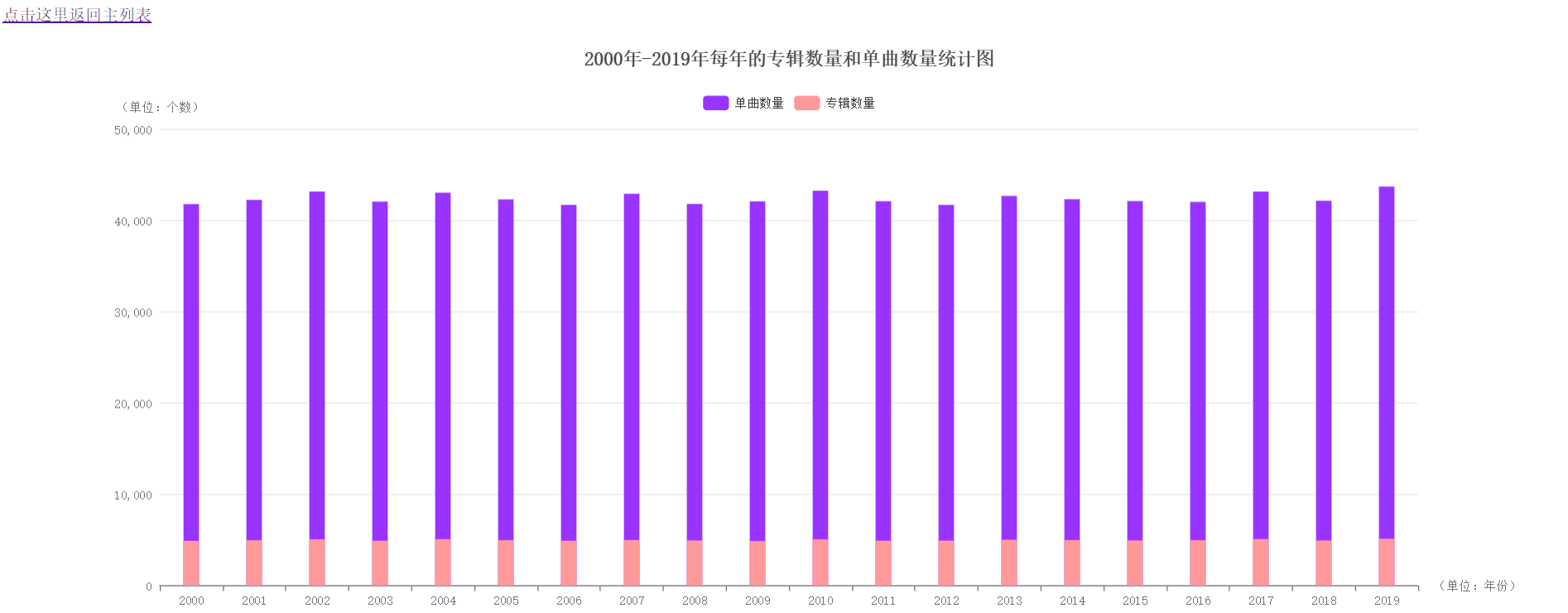 实验结果分析:由柱状图可知,这20年来,每年发布各种类型的专辑数量变化很小,基本稳定在5000左右。每年发布的单曲数量虽然轻微的波动,但是也较为稳定,大概为发行的专辑数量的10倍。
### (5)2000年-2019年总销量前五的专辑类型的各年份销量统计图
实验结果分析:由柱状图可知,这20年来,每年发布各种类型的专辑数量变化很小,基本稳定在5000左右。每年发布的单曲数量虽然轻微的波动,但是也较为稳定,大概为发行的专辑数量的10倍。
### (5)2000年-2019年总销量前五的专辑类型的各年份销量统计图
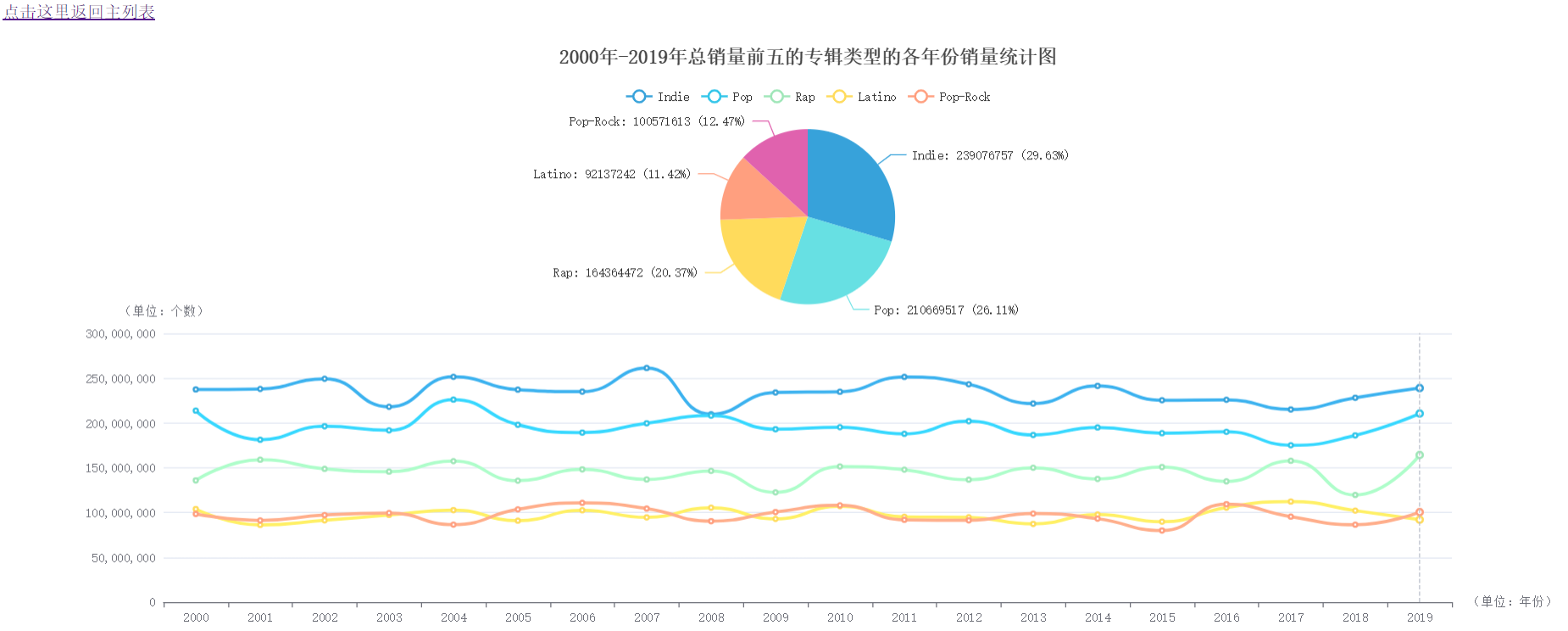 实验结果分析:由扇形图可知,这20年来,整个音乐市场占据大壁江山的专辑风格是Indie、Pop、Latino,它们对于音乐市场起了决定性的作用。再来看折线图,可以看到,随着年份的变化,Indie在2008年曾有过低潮期,Rap在2019年突然广受关注,其余风格的音乐专辑波动不大。
### (6)2000年-2019年总销量前五的专辑类型的在各个评价网站上的平均分数统计图
实验结果分析:由扇形图可知,这20年来,整个音乐市场占据大壁江山的专辑风格是Indie、Pop、Latino,它们对于音乐市场起了决定性的作用。再来看折线图,可以看到,随着年份的变化,Indie在2008年曾有过低潮期,Rap在2019年突然广受关注,其余风格的音乐专辑波动不大。
### (6)2000年-2019年总销量前五的专辑类型的在各个评价网站上的平均分数统计图
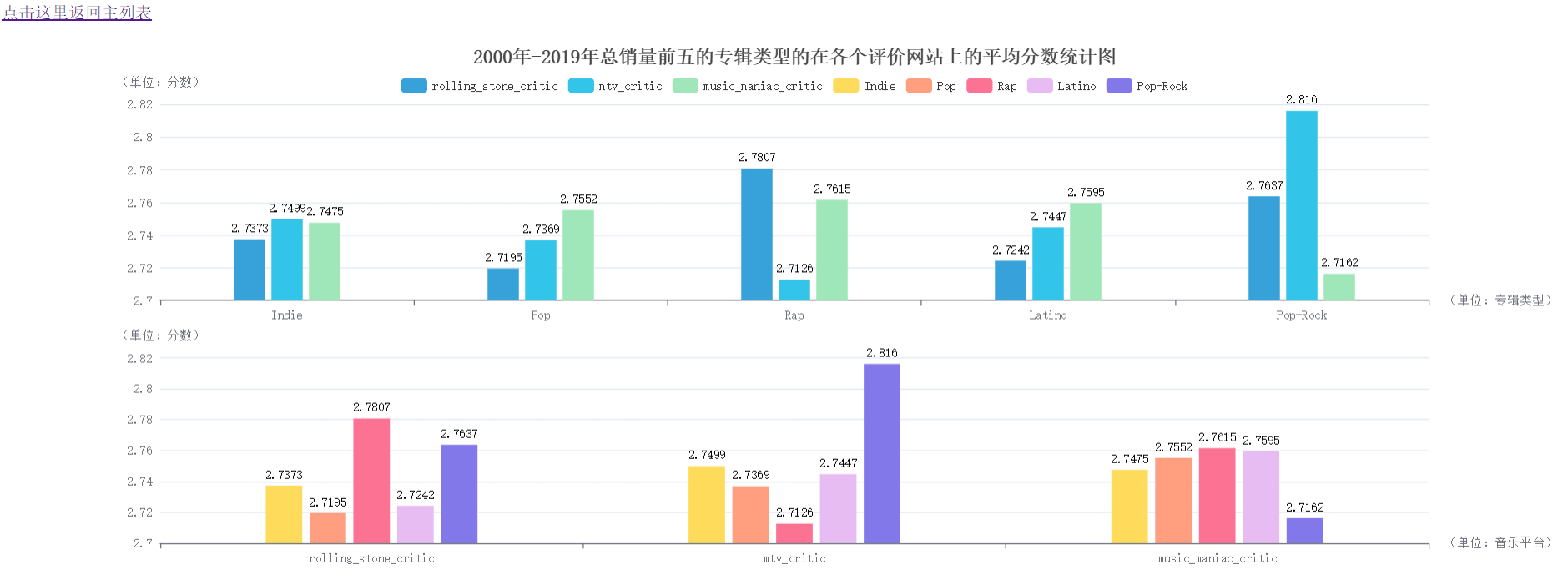 实验结果分析:不同的音乐平台对于不同风格的专辑喜好也不尽相同。由第一个柱状图可见,Indie风格在各个平台上的评分维持在2.73左右。Pop-Rock在mtv评分中独占上风。由第二个条形图可知,Rap在滚石网站上的评分较高,在mtv中评分较低。对于mtv评分,Pop-Rock占了绝对的优势。而对于音乐达人的评分,Pop-Rock评分较低,其余四大风格的专辑评分相差无几。
## Issue
### 1. JDK路径配置问题
在首次运行 main.py 如下命令时,
```python
from pyflink.dataset import ExecutionEnvironment
# 创建执行环境
exec_env = ExecutionEnvironment.get_execution_environment()
```
报错如下。
```shell
NotADirectoryError: [Errno 20] Not a directory: '/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_***/jre/bin/java/bin/java'
```
初步考虑 JDK1.8 的路径有错误。
运行如下命令进入 .bashrc 文件中解决。
```shell
vi ~/.bashrc
```
修改 JAVA_HOME变量 如下。
实验结果分析:不同的音乐平台对于不同风格的专辑喜好也不尽相同。由第一个柱状图可见,Indie风格在各个平台上的评分维持在2.73左右。Pop-Rock在mtv评分中独占上风。由第二个条形图可知,Rap在滚石网站上的评分较高,在mtv中评分较低。对于mtv评分,Pop-Rock占了绝对的优势。而对于音乐达人的评分,Pop-Rock评分较低,其余四大风格的专辑评分相差无几。
## Issue
### 1. JDK路径配置问题
在首次运行 main.py 如下命令时,
```python
from pyflink.dataset import ExecutionEnvironment
# 创建执行环境
exec_env = ExecutionEnvironment.get_execution_environment()
```
报错如下。
```shell
NotADirectoryError: [Errno 20] Not a directory: '/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_***/jre/bin/java/bin/java'
```
初步考虑 JDK1.8 的路径有错误。
运行如下命令进入 .bashrc 文件中解决。
```shell
vi ~/.bashrc
```
修改 JAVA_HOME变量 如下。
 再次运行 main.py 不再报错。
再次运行 main.py 不再报错。
# 致谢 课程最后感谢林老师的Flink和Spark的辛苦教学,以及提供给我们dblab网站上的学习资源。本次音乐专辑分析报告的代码将于2021年6月20号后开源于https://github.com/JoaquinChou/Flink_Music_Album_Data_Analysis 。
2. **安装Hadoop 3.1.4**:需要在Ubuntu16.04系统上安装Hadoop 3.1.4,可以参考这篇博客,完成Hadoop的安装。
3. **安装pyflink 1.13.1**:需要在Ubuntu16.04系统上安装pyflink 1.13.1,可以参考这篇博客或使用如下命令,完成pyflink1.13.1的安装。 ```shell pip install apache-flink==1.13.1 ``` 在上手之前,先大致介绍一下 PyFlink:
如上图所示。
(1) PyFlink 是 Flink 对 Java API 的一层封装,运行时会启动 JVM 来与 Python 进行通信。
(2) PyFlink 提供了多种不同层级的 API,层级越高封装程度越高(建议在 SQL API 或 Table API 进行编程),层级由高到低分别为:
**1) SQL API**
**2) Table API**
**3) DataStream API / DataSet API**
**4) Stateful Streaming Processing**
4. **开发工具:Pycharm**。安装Pycharm 2020.2专业破解版,点击这里查看破解教程。并且配置远程连接服务器,点击这里查看教程。 5. **Python版本:3.7**。在E盘中新建Flink_Music_Album_Data_Analysis文件夹,用PyCharm将其打开并新建static文件夹,再在static文件夹中新建js和data两个文件夹,如下所示。
6. **可视化工具:Echarts**。安装jQuery和Echarts:点击这里下载jQuery,将其另存为jquery.min.js文件,保存在static/js目录下。点击这里下载Echarts,将其另存为echarts.min.js文件,保存在static/js目录下。
到此为止,完成整个实验环境的搭建。
# 二、实验数据集
## 1. 数据集的说明
本次实验使用的数据集来自知名数据网站 Kaggle 的 music-label-dataset数据集,其中包含了10万条音乐专辑和歌手相关的数据。本次实验使用数据集中有关专辑的数据表 albums.csv 进行实验。你可以点击这里下载相关数据集。数据主要包含以下字段:
| 字段名称 | 解释 | 例子 |
| :------------------: | :-------------------------: | :---------------------------------: |
| id | 数据标号 | 1 |
| artist_id | 专辑对应歌手标号 | 1767 |
| album_title | 专辑名称 | Call me Cat Moneyless That Doggies |
| genre | 专辑风格 | Folk |
| year_of_pub | 专辑发行年份 | 2006 |
| num_of_tracks | 专辑中单曲数量 | 11 |
| num_of_sales | 专辑销量 | 905193 |
| rolling_stone_critic | 滚石网站的评分 | 4 |
| mtv_critic | 全球最大音乐电视网MTV的评分 | 1.5 |
| music_maniac_critic | 音乐达人的评分 | 3 |
## 2. 将数据集上传到分布式系统HDFS中 A. 为启动Hadoop中的HDFS组件,在Linux命令行窗口运行如下命令: ```shell $ /usr/local/hadoop/sbin/start-dfs.sh ``` B. 在服务器上创建Albums_data目录存放数据,在命令行运行下面命令: ```shell $ hdfs dfs -mkdir -p /home2/zgx/data/Albums_data ``` C. 把本地文件系统中的数据集albums.csv上传到分布式文件系统HDFS,在命令行运行下面命令: ```shell $ hdfs dfs -put albums.csv ``` 上传成功的结果图如下。
# 三、数据预处理
## 1. 建立工程文件
A. 在项目中创建main.py文件。
B. 在项目中创建templates文件夹,用于存放展示数据分析结果的html文件。
C. 创建文件夹名为utils的python工具包,并且创建statisitic_and_analysis.py和albums_to_wordcloud.py用于存放数据分析函数,同时在__ init __.py中添加如下代码,
```python
from utils.statisitic_and_analysis import *
from utils.albums_to_wordcloud import *
```
该代码能让数据分析函数直接被main.py调用。
D. 在项目中创建PyFlinkFlask.py文件。该文件存放Flask应用。用于调用Echarts实现界面展示。
实现后代码的结果如下所示。
## 2. 使用Flink将数据转为Table对象
由于读入的文件是csv文件,是结构化的数据。所以可以用pandas对象先读入csv文件,再调用PyFlink的Table API可以将pandas的DataFrame对象转化为Table对象进行分析。核心代码如下所示。
```python
pdf = pd.read_csv(data_dir + 'albums.csv')
table = t_env.from_pandas(pdf)
```
PyFlink1.14的API参考可以点击这里。调用from_pandas方法的好处在于可以将csv的所有列都读入一个临时表中,这样避免了使用CsvTable类去逐个调用每一列去组成一个临时表的繁琐操作,转为后的table打印出来的结果如下。
下面main.py中的代码段完成了文件从csv到pandas的DataFrame对象,再到Flink的Table对象的转化。
```python
from pyflink.table import EnvironmentSettings, TableEnvironment
import pandas as pd
if __name__ == "__main__":
# 1. 设置用于批处理的初始环境属性
settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()
t_env = TableEnvironment.create(settings)
# 设置处理数据的并行度
t_env.get_config().get_configuration().set_string("parallelism.default", "1")
# 设置读入数据的路径
data_dir = '/home2/zgx/data/Albums_data/'
# 2. 读入csv文件转为pandas的DataFrame对象
pdf = pd.read_csv(data_dir + 'albums.csv')
# 3. 将DataFrame对象转化为Flink的Table的对象
table = t_env.from_pandas(pdf)
# 将table对象进行处理并打印出来
table.execute().print()
```
至此,完成csv文件到Flink的Table对象的转换。
# 四、数据分析
本实验的数据分析代码放在主目录中的utils包的statisitic_and_analysis.py中,主要实现以下六个数据分析统计函数。
1. 2000年~2019年各类型专辑的数量的统计;
2. 2000年-2019年最受欢迎的50张专辑的词云图;
3. 2000年-2019年各类型专辑销量的统计;
4. 2000年-2019年每年的专辑数量和单曲数量的统计;
5. 2000年-2019年总销量前五的专辑类型的各年份销量的统计;
6. 2000年-2019年总销量前五的专辑类型在各个评价网站上平均分数的统计。
为了方便数据可视化,对于每个不同的分析,都将分析结果导出json文件由web页面读取并且进行可视化操作。
以下将详细介绍utils包中的6个数据分析函数。
## 1. 2000年~2019年各类型专辑的数量的统计
为了统计统计20年间各类风格的音乐专辑的总数量,复制以下代码到statisitic_and_analysis.py。
```python
from pyflink.table.expressions import lit, col
import json
# 第1个图:统计20年间各类风格的音乐专辑的总数量
def genre(table, json_save_dir, file_name):
table_results = table.group_by(col("genre")).select(col("genre"), lit(1).count.alias("genre_num")).execute()
# table_results.print()
res = []
with table_results.collect() as results:
for result in results:
res.append(result.__dict__.get('_values'))
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(res))
f.close()
```
上述函数利用Flink中的Table API提取出不同风格的专辑出现的次数,最后的结果保存于json中。函数返回的数据格式是
```json
[["Folk", 1912], ["Metal", 1934],...,]
```
## 2. 2000年-2019年最受欢迎的50张专辑的词云图
为了统计20年间最受欢迎的50张专辑,复制以下代码到statisitic_and_analysis.py。
```python
# 第2个图:统计20年间销量在前50的音乐专辑名称并用词云显示
def top_50_albums(table, json_save_dir, file_name):
table_results = table.select(col("album_title"), col("num_of_sales")).order_by(
col("num_of_sales").desc).limit(50).execute()
ans = {}
with table_results.collect() as results:
for result in results:
ans[result.__dict__.get('_values')[0]] = result.__dict__.get('_values')[1] - 999000
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
为了生成词云图,复制以下代码到albums_to_wordcloud.py。
```python
from wordcloud import WordCloud
import json
def analysis_top_50_albums():
data1 = json.load(open('../static/data/top_50_albums.json'))
wc1 = WordCloud(background_color='white',
).generate_from_frequencies(data1)
wc1.to_file("../templates/word_cloud.jpg")
```
为实现词云图,先调用table中的order_by()方法将专辑名称按销量降序排列,再用limit()方法统计出销量前50的专辑名称。最后使用python中的WordCloud库实现词云的生成。
## 3. 2000年-2019年各类型专辑销量的统计
为了统计20年间各类型专辑的销量,复制以下代码到statisitic_and_analysis.py。
```python
# 第3个图:各类型专辑的销量统计图
def album_sales(table, json_save_dir, file_name):
table_results = table.group_by(col("genre")).select(col("genre"),
col("num_of_sales").sum.alias(
"each_album_genre_sales")).execute()
# table_results.print()
res = []
with table_results.collect() as results:
for result in results:
res.append(result.__dict__.get('_values'))
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(res))
f.close()
```
上述函数利用Flink中的Table API中col的sum方法,将不同年份同一类型专辑的销量进行求和,最后的结果保存于json中。函数返回的数据格式是
```json
[["Folk", 965444874], ["Metal", ***3639223],...]
```
## 4. 2000年-2019年每年的专辑数量和单曲数量的统计
为了统计20年间每年的专辑数量和单曲数量,复制以下代码到statisitic_and_analysis.py。
```python
# 第4个图:统计每年的专辑数量和单曲数量
def year_albums_and_tracks(table, json_save_dir, file_name):
table_results = table.group_by(col("year_of_pub")).select(col("year_of_pub"),
col("genre").count.alias("genres_num"),
col("num_of_tracks").sum.alias("tracks_num")).order_by(
col("year_of_pub").asc).execute()
# table_results.print()
ans = {"tracks": [], "years": [], "albums": []}
with table_results.collect() as results:
for result in results:
# res.append(result.__dict__.get('_values'))
ans["tracks"].append(result.__dict__.get('_values')[2])
ans["years"].append(result.__dict__.get('_values')[0])
ans["albums"].append(result.__dict__.get('_values')[1])
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
上述函数将统计的每年的单曲数、年份、每年专辑类型数存于ans字典中,最后的结果保存于json中。函数返回的数据格式是
```json
{
"tracks": [41816,...],
"years": [2000,...],
"albums": [4921,...]
}
```
## 5. 2000年-2019年总销量前五的专辑类型的各年份销量的统计
为了统计20年间总销量前五的专辑类型的各年份销量,复制以下代码到statisitic_and_analysis.py。
```python
# 返回总销量是前五的专辑类型
def top_5_genres_list(table):
table_results = table.group_by(col("genre")).select(col("genre"),
col("num_of_sales").sum.alias("each_album_sales")).order_by(
col("each_album_sales").desc).limit(5).execute()
list = []
with table_results.collect() as results:
for result in results:
# print(result.__dict__.get('_values')[0])
list.append(result.__dict__.get('_values')[0])
# print(list)
return list
# 第五个图:总销量前五类型的专辑各年份销量
def top_5_genres_years_sales(table, genres_list, json_save_dir, file_name):
ans = {}
for genre in genres_list:
table_results = table.filter(col("genre") == genre).group_by(col("year_of_pub")).select(col("year_of_pub"), col(
"num_of_sales").sum.alias(
"years_of_sales")).order_by(
col("year_of_pub").asc).execute()
list = []
with table_results.collect() as results:
for result in results:
result.__dict__.get('_values').insert(0, genre)
list.append(result.__dict__.get('_values'))
ans[genre] = list
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(ans))
f.close()
```
上述函数做了两件事情,首先先用函数top_5_genres_list()找到整个数据集中总销量为前五的专辑,再将前五专辑送入函数top_5_genres_years_sales()中,统计各年份的销量。最后的结果保存于json中。函数返回的数据格式是
```json
{
"Indie": [["Indie", 2000, 237517311],...
}
```
## 6. 2000年-2019年总销量前五的专辑类型在各个评价网站上平均分数的统计
为了统计20年间总销量前五的专辑类型在各个评价网站上平均分数,复制以下代码到statisitic_and_analysis.py。
```python
# 第六个图:总销量前五专辑类型在不同评分系统的平均分数
def top_5_genres_avg_scores(table, genres_list, json_save_dir, file_name):
# genres_list = top_5_genres_list(table)
list = []
for genre in genres_list:
table_results = table.filter(col("genre") == genre).select(col("rolling_stone_critic").avg,
col("mtv_critic").avg,
col("music_maniac_critic").avg).execute()
with table_results.collect() as results:
for result in results:
temp = [round(x, 4) for x in result.__dict__.get('_values')]
temp.insert(0, genre)
list.append(temp)
f = open(json_save_dir + file_name, 'w')
f.write(json.dumps(list))
f.close()
```
上述函数使用Flink Table API中col的avg函数,将各个网站的评分直接取平均,最后的结果保存于json中。函数返回的数据格式是
```json
[["Indie", 2.7373, 2.7499, 2.7475],
["Pop", 2.7195, 2.7369, 2.7552],...
]
```
# 五、可视化展示
本实验的可视化是基于echarts实现的,实现的可视化页面部署在基于flask框架的web服务器上。
## 1. 建立Flask应用
在PyFlinkFlask.py中复制以下代码:
```python
from flask import render_template
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
# 使用render_template的方法来渲染页面
return render_template('index.html')
@app.route('/
点击后可以看到如下界面。
上述是本次实验的各个数据分析统计图的链接。
### (1)2000年-2019年各类型专辑的数量统计图
实验结果分析:由玫瑰花图可知,这20年来,比较受欢迎的前8的专辑风格分别是Indie、Pop、Rap、Pop-Rock、Dance、Rock、Punk、Latino。
### (2)2000年-2019年最受欢迎的50张专辑词云图
实验结果分析:由词云图可知,这20年来,比较受欢迎的前3专辑是Decent Waterbuck、Little of Pahari、Every Country Toys Chameleon。
### (3)2000年-2019年各类型专辑销量统计图
实验结果分析:由柱状图可知,这20年来,比较畅销的前8专辑风格的分别是Indie、Pop、Rap、Dance、Latino、Pop-Rock、Rock、Punk。这种结果与上述玫瑰花图的结果不谋而合,这些类型的专辑比较广为大众认可。所以畅销量较大。
### (4)2000年-2019年每年的专辑数量和单曲数量统计图
实验结果分析:由柱状图可知,这20年来,每年发布各种类型的专辑数量变化很小,基本稳定在5000左右。每年发布的单曲数量虽然轻微的波动,但是也较为稳定,大概为发行的专辑数量的10倍。
### (5)2000年-2019年总销量前五的专辑类型的各年份销量统计图
实验结果分析:由扇形图可知,这20年来,整个音乐市场占据大壁江山的专辑风格是Indie、Pop、Latino,它们对于音乐市场起了决定性的作用。再来看折线图,可以看到,随着年份的变化,Indie在2008年曾有过低潮期,Rap在2019年突然广受关注,其余风格的音乐专辑波动不大。
### (6)2000年-2019年总销量前五的专辑类型的在各个评价网站上的平均分数统计图
实验结果分析:不同的音乐平台对于不同风格的专辑喜好也不尽相同。由第一个柱状图可见,Indie风格在各个平台上的评分维持在2.73左右。Pop-Rock在mtv评分中独占上风。由第二个条形图可知,Rap在滚石网站上的评分较高,在mtv中评分较低。对于mtv评分,Pop-Rock占了绝对的优势。而对于音乐达人的评分,Pop-Rock评分较低,其余四大风格的专辑评分相差无几。
## Issue
### 1. JDK路径配置问题
在首次运行 main.py 如下命令时,
```python
from pyflink.dataset import ExecutionEnvironment
# 创建执行环境
exec_env = ExecutionEnvironment.get_execution_environment()
```
报错如下。
```shell
NotADirectoryError: [Errno 20] Not a directory: '/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_***/jre/bin/java/bin/java'
```
初步考虑 JDK1.8 的路径有错误。
运行如下命令进入 .bashrc 文件中解决。
```shell
vi ~/.bashrc
```
修改 JAVA_HOME变量 如下。
再次运行 main.py 不再报错。
# 致谢 课程最后感谢林老师的Flink和Spark的辛苦教学,以及提供给我们dblab网站上的学习资源。本次音乐专辑分析报告的代码将于2021年6月20号后开源于https://github.com/JoaquinChou/Flink_Music_Album_Data_Analysis 。
近期下载者:
相关文件:
收藏者: