Super-Spider
所属分类:数据采集/爬虫
开发工具:Python
文件大小:89KB
下载次数:0
上传日期:2017-05-26 00:42:38
上 传 者:
sh-1993
说明: 根据腾讯安全应急响应中心的架构编写的一款超强爬虫(广度优先搜索)
(A super strong crawler (breadth first search) based on the architecture of Tencent Security Emergency Response Center)
文件列表:
Analysis (0, 2017-05-26)
Analysis\DomAnalysis.py (2680, 2017-05-26)
Analysis\DomAnalysis.pyc (2063, 2017-05-26)
Analysis\FilterURL.py (798, 2017-05-26)
Analysis\FilterURL.pyc (1677, 2017-05-26)
Analysis\__init__.py (0, 2017-05-26)
Analysis\__init__.pyc (150, 2017-05-26)
DuplicateRemoval (0, 2017-05-26)
DuplicateRemoval\DuplicateRemoval.py (974, 2017-05-26)
DuplicateRemoval\DuplicateRemoval.pyc (1437, 2017-05-26)
DuplicateRemoval\__init__.py (0, 2017-05-26)
DuplicateRemoval\__init__.pyc (158, 2017-05-26)
Images (0, 2017-05-26)
Images\Crawler.png (30465, 2017-05-26)
Images\architecture.png (47182, 2017-05-26)
ShowResult.txt (1187, 2017-05-26)
db (0, 2017-05-26)
db\5c016e8f0f95f039102cbe8366c5c7f3.db3 (3072, 2017-05-26)
db\75a8d2e11c306c18d658c410533ebf26.db3 (3072, 2017-05-26)
db\789c09d92dae4d471033262d4d8b46ae.db3 (3072, 2017-05-26)
db\f528764d624db129b32c21fbca0cb8d6.db3 (3072, 2017-05-26)
downloader.py (1875, 2017-05-26)
downloader.pyc (2742, 2017-05-26)
superspider.py (2181, 2017-05-26)
## SuperSpider
这是一款我非常喜欢的爬虫,和以往开发的爬虫不一样,这次爬虫从功能和架构上都有了突飞猛进的进步。众所周知,爬虫在各个领域都有着或重或轻的应用。像在数据挖掘领域需要爬虫将大量数据高效的保存至本地文件中。又或者在制作WEB扫描器的时候,爬虫站在整个扫描器的最前线。不仅如此,连著名的google和百度都是有强大的爬虫程序。由此可见爬虫程序可靠,高效的特性对于后期数据处理有着不可替代的作用。
因为编写一款功能完善高效的爬虫是一个复杂并且需要不断学习的过程,这款工具现在已经能满足基本需求,但是还是会长期继续更新,敬请关注。
### 什么是爬虫?
网络爬虫(web spider)是一个自动的通过网络抓取互联网上的网页的程序。
### 这款爬虫工具的架构
这款工具的架构采用的是腾讯安全应急响应中心一篇博文中给出的一个架构(博文链接:[打造功能强大的爬虫利器](https://security.tencent.com/index.php/blog/msg/34)。之所以选择这个架构,是因为这个架构合理,便于维护和拓展,具有权威性。虽然这篇文章对爬虫架构和每个部分的功能有所说明,但是说明不够详细和完善,有很多可以补充的空间,而且官方并没有没有给出代码细节。
因此我以这篇博文为基础添加许多自己的想法构建了这款SuperSpider工具。爬虫架构如下:
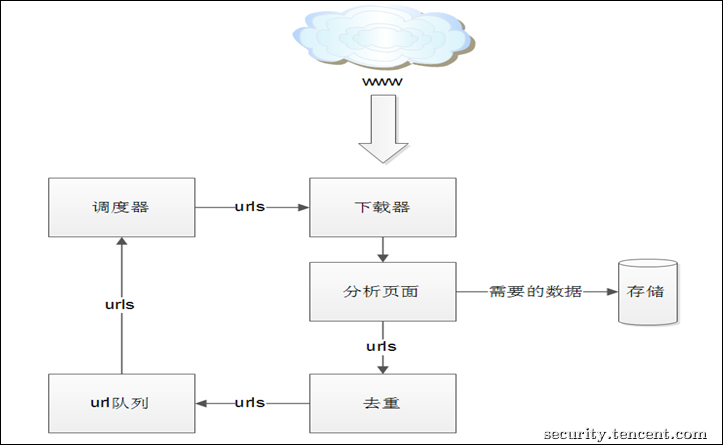
下面我来详细说明一下每个模块:
#### 1.分析页面,主要包括以下内容:
- 静态页面链接分析
- javascript动态解析
- 自动分析表单
- 自动交互
- hook所有的网络请求
#### 2.调度器
这里调度器使用广度优先搜索算法策略,主要是觉得采用这种策略易于编程。
#### 3.去重模块
去重是为了提高效率,在腾讯那篇博文中,它提到一种需要去重的情况:大部分网站中日期作为其url的组成部分,尤其是门户网站。SuperSpider使用将数字替换成d+的算法对url进行去重。例如:
http://video.sina.com.cn/ent/s/h/2010-01-10/163961994.shtml?a=1&b=10
http://video.sina.com.cn/ent/s/h/2009-12-10/16334456.shtml?a=12&b=67
对数字进行模式处理为:
http://video.sina.com.cn/ent/s/h/d+-d+-d+/d+.shtml?a=d+&b=d+
如果链接1已经爬取过,链接2与链接1类似, 不重复爬取。试验证明这种方法简捷高效,漏爬率极低,大大提升扫描器的效率.
除此之外,我还增加了更多的去重情况:
- 将#Hash后面的内容 去除
- 将链接末尾的?,&,=去除
- 对于同一个提交参数的值都视为一类,除了特别的几种参数
#### 4.标准化
这个是许多谈及爬虫架构没有提到的,而我认为非常核心的一个步骤。如果用户输入或者网页开发者在网页中的链接是一个格式正常URL,爬虫工作问题不大,可是很多时候会出现HTTP:///www.baidu.com///这类的链接,又或者是结尾很多##等等,这种不规范如果要在每一个需要规范的地方处理会带来很多问题,最好的办法就是在每一个链接呗爬取后立即做出统一的规范处理,一遍后面的任意使用。
### 爬虫的具体实现
腾讯博文给出了一个很小的代码师范,但是这个代码一是对于不熟悉PyQt4的开发者来说很难封装成一个可调度页面抓取接口,而且容易报错。二是不符合我的开发习惯,所以完全采用了自己编写的类Crawler 如下:

除此之外,这款工具纯Python2.7.9构建,目前需要的第三方依赖如下:
- PyQt4
- requests
### 数据保存
我在构建这款工具的时候,采用数据库的方式,由去重模块将不重复链接保存在SQLite3数据库中,最后的文件在db下面。
文件名是用户输入的URL经过标准化后的字符串md5加密。
### 使用方法
目前暂时没提供命令行操作,需要有python编辑器,修改Spider_url为目标URL,然后运行。
### 问题
暂时没有解决在爬取某些网页时如果阻塞等待目标响应问题。
近期下载者:
相关文件:
收藏者: