sentence-similarity
所属分类:聚类算法
开发工具:Python
文件大小:8172KB
下载次数:0
上传日期:2020-11-17 15:34:54
上 传 者:
sh-1993
说明: 问题句子相似度计算,即给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义。
(The problem sentence similarity calculation is to determine whether the two sentences described by the user in the customer service represent the same semantics with an algorithm.)
文件列表:
build_input.py (3977, 2018-12-05)
data_loader.py (1753, 2018-12-05)
evalute.py (1780, 2018-12-05)
input (0, 2018-12-05)
input\atec (0, 2018-12-05)
input\atec\atec_nlp_sim_train.csv (3485318, 2018-12-05)
input\atec\atec_nlp_sim_train_add.csv (5625804, 2018-12-05)
input\ccks (0, 2018-12-05)
input\ccks\task3_dev.txt (760958, 2018-12-05)
input\ccks\task3_train.txt (7355965, 2018-12-05)
input\ccks\test_with_id.txt (8555401, 2018-12-05)
model (0, 2018-12-05)
model\model.png (23854, 2018-12-05)
model\result_atec.png (27266, 2018-12-05)
model\result_ccks.png (25260, 2018-12-05)
model\vocab.txt (5975, 2018-12-05)
train_siamese_network.py (3955, 2018-12-05)
# sentence-similarity
问题句子相似度计算,即给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义。
## 句子相似度判定
今年和去年前后相继出现了多个关于句子相似度判定的比赛,即得定两个句子,用算法判断是否表示了相同的语义或者意思。
`其中第4、5这个2个比赛数据集格式比较像,请见` [sent_match](https://github.com/yanqiangmiffy/sent_match),`,2、3 的数据集格式比较像,本仓库基于2、3数据集做实验`
下面是比赛的列表:
- 1 [Quora Question Pairs](https://www.kaggle.com/c/quora-question-pairs)
> The goal of this competition is to predict which of the provided pairs of questions contain two questions with the same meaning.
> [数据集](https://www.kaggle.com/c/quora-question-pairs/data)未经过脱敏处理,用真实的英文单词标识
- 2 [ ATEC学习赛:NLP之问题相似度计算](https://dc.cloud.alipay.com/index#/topic/intro?id=8)
> 问题相似度计算,即给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义。
> [数据集](https://dc.cloud.alipay.com/index#/topic/data?id=8)未经过脱敏处理
> 示例:
> 1. “花呗如何还款” --“花呗怎么还款”:同义问句
> 2. “花呗如何还款” -- “我怎么还我的花被呢”:同义问句
> 3. “花呗分期后逾期了如何还款”-- “花呗分期后逾期了哪里还款”:非同义问句
> 对于例子a,比较简单的方法就可以判定同义;对于例子b,包含了错别字、同义词、词序变换等问题,两个句子乍一看并不类似,想正确判断比较有挑战;对于例子c,两句> 话很类似,仅仅有一处细微的差别 “如何”和“哪里”,就导致语义不一致。"""
- 3 [CCKS 2018 微众银行智能客服问句匹配大赛](https://biendata.com/competition/CCKS2018_3/leaderboard/)
> 与基于Quora的的的语义等价判别相同,本次评测任务的主要目标是针对中文的真实客服语料,进行问句意图匹配。集给定两个语句,要求判定两者意图是否相同或者相近。所有语料来自原始的银行领域智能客服日志,并经过了筛选和人工的意图匹配标注。
> [数据集](https://biendata.com/competition/CCKS2018_3/data/)经过脱敏处理
> 输入:一般几天能通过审核\ t一般审核通过要多久
> 输出:1
- 4 [CHIP 2018-第四届中国健康信息处理会议(CHIP)](https://biendata.com/competition/chip2018/)
> 本次评测任务的主要目标是针对中文的真实患者健康咨询语料,进行问句意图匹配。给定两个语句,要求判定两者意图是否相同或者相近。所有语料来自互联网上患者真实> 的问题,并经过了筛选和人工的意图匹配标注。平安云将为报名的队伍提供GPU的训练环境。
> [数据集](https://biendata.com/competition/chip2018/data/)经过脱敏处理,问题由数字标示
> 训练集包含20000条左右标注好的数据(经过脱敏处理,包含标点符号),供参赛人员进行训练和测试。 测试集包含10000条左右无label的数据(经过脱敏处理,包含标点> 符号)。选手需要对测试集数据的label进行预测并提交。测试集数据作为AB榜的评测依据。
- 5 [第三届魔镜杯大赛](https://ai.ppdai.com/mirror/goToMirrorDetail?mirrorId=1)
> 智能客服聊天机器人场景中,待客户提出问题后,往往需要先计算客户提出问题与知识库问题的相似度,进而定位最相似问题,再对问题给出答案。本次比赛的题目便是问 > 题相似度算法设计。
> [数据集](https://ai.ppdai.com/mirror/goToMirrorDetail?mirrorId=1)经过脱敏处理,问题由数字标示
> 为保护用户隐私并保证比赛的公平公正,所有原始文本信息都被编码成单字ID序列和词语ID序列。单字包含单个汉字、英文字母、标点及空格等;词语包含切词后的中> 文词语、英文单词、标点及空格等。单字ID和词语ID存在于两个不同的命名空间,即词语中的单字词或者标点,和单字中的相同字符及相同标点不一定有同一个ID。其> > 中,单字序列以L开头,词语序列以W开头。
## Siamese Network
MaLSTM’s architecture — Similar color means the weights are shared between the same-colored elements
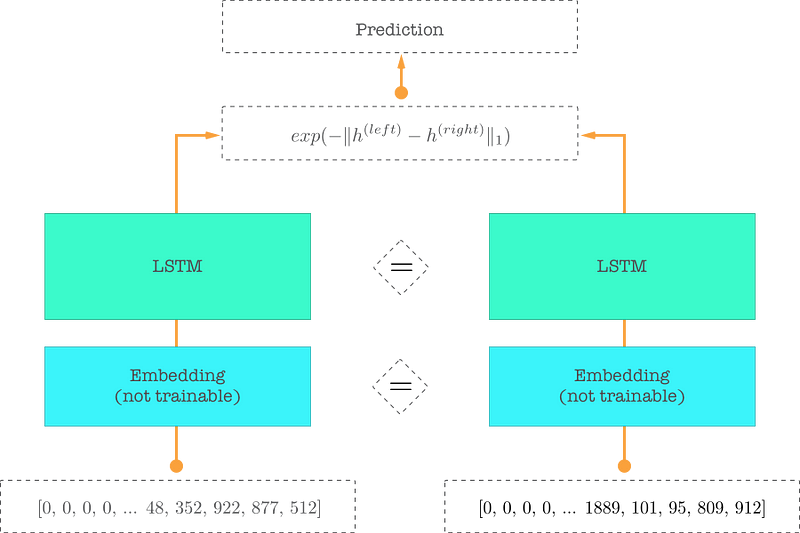
- 词向量是基于字符级别的,在我印象里一般是字符级的效果比较好
- LSTM训练出来两个问题的语义向量,然后再给相似度函数`MaLSTM similarity function`
```text
def exponent_neg_manhattan_distance(sent_left, sent_right):
'''基于曼哈顿空间距离计算两个字符串语义空间表示相似度计算'''
return K.exp(-K.sum(K.abs(sent_left - sent_right), axis=1, keepdims=True))
```
我们仔细看下这个函数的输出是0-1,也就是我们预测概率
- 训练结果:
在ccks任务上:`acc: 0.8372 - val_loss: 0.4316 - val_acc: 0.8047`

在atec任务上:`loss: 0.3302 - acc: 0.8570 - val_loss: 0.5244 - val_acc: 0.7702`

## 更多资料
1. [How to predict Quora Question Pairs using Siamese Manhattan LSTM](https://medium.com/mlreview/implementing-malstm-on-kaggles-quora-question-pairs-competition-8b31b0b16a07)
2. [nlp中文本相似度计算问题](https://blog.csdn.net/u014248127/article/details/80736044)
3. [语义相似度计算各种算法实现汇总](https://github.com/yanleping/similarity)
4. [距离度量以及python实现(一)](https://www.cnblogs.com/denny402/p/7027954.html)
5. [从Kaggle赛题: Quora Question Pairs 看文本相似性/相关性](https://zhuanlan.zhihu.com/p/35093355)
6. [SiameseSentenceSimilarity](https://github.com/liuhuanyong/SiameseSentenceSimilarity)
7. [QuoraDQBaseline](https://github.com/erogol/QuoraDQBaseline)
近期下载者:
相关文件:
收藏者: