.ipynb_checkpoints/ (0, 2016-02-24)
.ipynb_checkpoints/Crowdsourcing novelty features for news and tweets-checkpoint.ipynb (255792, 2016-02-24)
Crowdsourcing novelty features for news and tweets.ipynb (776977, 2016-02-24)
aggregate/ (0, 2016-02-24)
aggregate/aggregatedResults_newsArticles.csv (491459, 2016-02-24)
aggregate/aggregatedResults_tweets2014&2015.csv (1395098, 2016-02-24)
aggregate/histogramRelevantTweets.csv (116, 2016-02-24)
aggregate/orderedNewsSnippetsBySentiments.csv (89674, 2016-02-24)
aggregate/orderedSnippetsByRelevance.csv (88934, 2016-02-24)
aggregate/orderedSnippetsBySentiments.csv (89674, 2016-02-24)
aggregate/orderedTweetsByMentions.csv (311963, 2016-02-24)
aggregate/orderedTweetsByRelevance.csv (324126, 2016-02-24)
aggregate/orderedTweetsBySentiments.csv (311963, 2016-02-24)
aggregate/sentimentAnalysis_newsTitles.csv (3852, 2016-02-24)
aggregate/snippetsPositionInArticle.csv (171, 2016-02-24)
aggregate/tweetsChangeInSentiment.csv (1190, 2016-02-24)
img/ (0, 2016-02-24)
img/taskrelevancenews-withoutInstructions.jpg (166565, 2016-02-24)
img/taskrelevancenews.jpg (243539, 2016-02-24)
img/taskrelevancetweets-withoutInstructions.jpg (119781, 2016-02-24)
img/taskrelevancetweets.jpg (233980, 2016-02-24)
img/tasksentimentnews-withoutInstructions.jpg (112968, 2016-02-24)
img/tasksentimentnews.jpg (189269, 2016-02-24)
img/tasksentimenttweets-withoutInstructions.jpg (124423, 2016-02-24)
img/tasksentimenttweets.jpg (202079, 2016-02-24)
img/workflow_salient_features.jpg (593303, 2016-02-24)
img/workflow_salient_features_news.jpg (512076, 2016-02-24)
img/workflow_salient_features_tweets.jpg (471435, 2016-02-24)
input/ (0, 2016-02-24)
input/seedWords_domainExperts.csv (747, 2016-02-24)
raw/ (0, 2016-02-24)
raw/Relevance Analysis/ (0, 2016-02-24)
raw/Relevance Analysis/News/ (0, 2016-02-24)
raw/Relevance Analysis/News/f706807.csv (99882, 2016-02-24)
raw/Relevance Analysis/News/f706809.csv (100083, 2016-02-24)
raw/Relevance Analysis/Tweets/ (0, 2016-02-24)
raw/Relevance Analysis/Tweets/f721749.csv (289442, 2016-02-24)
raw/Relevance Analysis/Tweets/f721753.csv (358053, 2016-02-24)
raw/Relevance Analysis/Tweets/f721756.csv (265755, 2016-02-24)
... ...
# Crowdsourcing salient information from news articles and tweets
[](https://zenodo.org/badge/latestdoi/19180/CrowdTruth/Salience-In-News-And-Tweets)
This repository contains preliminary work results for identifying linguistic features for novelty detection in news articles and tweets. We report here results of a crowdsourcing experimental pipeline of assessing the relevance of various tweets and news article snippets and the sentiments and intensities they indicate. The main focus of this dataset if to gather initial relevant and novel information insights, with regard to the event of "
whaling".
All the crowdsourcing experiments were performed through the CrowdTruth platform, while the results were processed and analyzed using the CrowdTruth methodology and metrics. For more information, check the
CrowdTruth website. For gathering the annotated data, we used the
CrowdFlower marketplace.
## Check the Results & Download the Data:
Salience-In-News-And-Tweets
## Table of Contents:
* [Dataset Files](#datasetfiles)
* [Crowdsourcing Experiments](#crowdsourcingexperiments)
* [Relevance Analysis Task on News Articles (DS1)](#taskrelevancenews)
* [Sentiment Analysis Task on News Articles (DS1)](#tasksentimentnews)
* [Relevance Analysis Task on Tweets (DS2&DS3)](#taskrelevancetweets)
* [Sentiment Analysis Task on Tweets (DS2&DS3)](#tasksentimenttweets)
* [Experiments Results](#results)
* [Relevance Analysis Task on News Articles (DS1)](#resultsrelevancenews)
* [Sentiment Analysis Task on News Articles (DS1)](#resultssentimentnews)
* [Relevance Analysis Task on Tweets (DS2&DS3)](#resultsrelevancetweets)
* [Sentiment Analysis Task on Tweets (DS2&DS3)](#resultssentimenttweets)
## Dataset Files:
```
|--/aggregate
```
Various aggregated datasets collected as part of collecting the salient features in news articles and tweets workflow. We describe here the most important files:
```
|--/aggregate/aggregatedResults_newsArticles.csv
```
This file contains the processed ground truth for the news articles related to the whaling event, in comma-separated format. The file contains aggregated results of the snippets relevance and the snippets and relevant event mentions sentiment and intensity. The columns are:
* *Dataset*: reference to the dataset, news - DS1
* *Unit Id*: unique ID of the data entry
* *Title Id*: news article unique title ID
* *Title*: news article title
* *Snippet Id*: news article unique snippet ID
* *Snippet*: news article snippet
* *Overlapping Snippet*: binary value describing whether the snippet contains overlapping tokens with the title (1) or not (0)
* *Snippet Relevance Score*: the snippet relevance score; computed using the cosine similarity measure, shows the likelihood that the given snippet is relevant for the news article title
* *Number of Relevant Mentions*: total number of relevant event mentions identified by the crowd in the given snippet
* *Overall Sentiment-Intensity*: binary value describing whether the following columns contain sentiment and intensity scores for the snippet (1) or for the relevant event mentions identified in the given snippet (0)
* *Relevant Mention*: relevant event mention
* *Relevant Mention Score*: the event mention relevance score; computed using the cosine similarity measure, shows the likelihood that the given mention in the snippet is relevant for the news article title
* *Positive Sentiment, Negative Sentiment, Neutral Sentiment*: the sentiment scores of the snippets and event mentions; computed using the cosine similarity measure, shows the likelihood that the given snippet or mention expresses the given sentiment
* *High Intensity, Low Intensity, Medium Intensity*: the intensity scores of the snippets and event mentions; computed using the cosine similarity measure, shows the likelihood that the given snippet or mention expresses a sentiment with the given intensity
```
|--/aggregate/aggregatedResults_tweets2014&2015.csv
```
This file contains the processed ground truth for the tweets related to the whaling event - from 2014 and 2015, in comma-separated format. The file contains aggregated results of the tweets relevance, tweets relevant event mentions and the sentiment and intensity of the overall tweet and event mentions. The columns are:
* *Dataset*: reference to the dataset, tweets 2014 - DS2, tweets 2015 - DS3
* *Tweet Id*: unique ID of the tweet data entry
* *Tweet Author*: tweet author
* *Tweet Date*: tweet date
* *Tweet Seed Index*: unique tweet-event ID
* *Tweet Content*: tweet content
* *Tweet Event Relevance Score*: the tweet relevance score with regard to the whaling event; computed using the cosine similarity measure, shows the likelihood that the given tweet is relevant for the whaling event
* *Number of Relevant Mentions*: total number of relevant event mentions identified by the crowd in the given tweet
* *Overall Sentiment-Intensity*: binary value describing whether the following columns contain sentiment and intensity scores for the tweet (1) or for the relevant event mentions identified in the given tweet (0)
* *Relevant Mention*: relevant event mention
* *Relevant Mention Score*: the event mention relevance score; computed using the cosine similarity measure, shows the likelihood that the given mention in the tweet is relevant for the whaling event
* *Positive Sentiment, Negative Sentiment, Neutral Sentiment*: the sentiment scores of the tweet and event mentions; computed using the cosine similarity measure, shows the likelihood that the given tweet or mention expresses the given sentiment
* *High Intensity, Low Intensity, Medium Intensity*: the intensity scores of the tweet and event mentions; computed using the cosine similarity measure, shows the likelihood that the given tweet or mention expresses a sentiment with the given intensity
```
|--aggregate/orderedSnippetsByRelevance.csv
```
The file contains the relevant news snippets ordered by their relevance score. The overlapping news snippets are ordered in a descending way, while the non-overlapping news snippets are ordered ascending.
```
|--aggregate/snippetsPositionInArticle.csv
```
The file contains measures for snippets relevance with regard to their position in the news articles.
```
|--aggregate/orderedNewsSnippetsBySentiments.csv
```
The file contains the relevant news snippets ordered by their sentiments: positive sentiment - descending, negative sentiment - ascending.
```
|--aggregate/orderedTweetsByRelevance.csv
```
The file contains the relevant tweets ordered by their relevance score.
```
|--aggregate/orderedTweetsByMentions.csv
```
The file contains the relevant tweets ordered by their total number of relevance event mentions.
```
|--aggregate/histogramRelevantTweets.csv
```
The file contains the number of relevant tweets for each relevance score intervals.
```
|--aggregate/orderedTweetsBySentiments.csv
```
The file contains the relevant tweets ordered by their sentiments: positive sentiment - descending, negative sentiment - ascending.
```
|--aggregate/tweetsChangeInSentiment.csv
```
The file contains relevant event mentions in tweets that refer to "*whaling ban*". Each such relevant event mention has the associated sentiment and intensity acores.
```
|--/input
| |--/seedWords_domainExperts.csv
```
The file contains relevant seed words for the whaling event, obtained from the social sciences domain experts. Each column of the file represents a type: *Event*, *Location*, *Actor/Organization*, *Other*
```
|--/raw
| |--/Relevance Analysis
| | |--/News
| | |--/Tweets
| |--/Sentiment Analysis
| | |--/News
| | |--/Tweets
```
The raw data collected from crowdsourcing for each of the 2 tasks.
## Crowdsourcing Experiments:
The overall
workflow consists of two crowdsourcing tasks for each dataset:
1.
Relevance Analysis: to identify the relevant news snippets and tweets;
2.
Sentiment Analysis: to identify (1) the sentiment of each relevant event mention in all the relevant news snippets and tweets and (2) the overall sentiment of all the relevant news snippets and tweets.
During the "
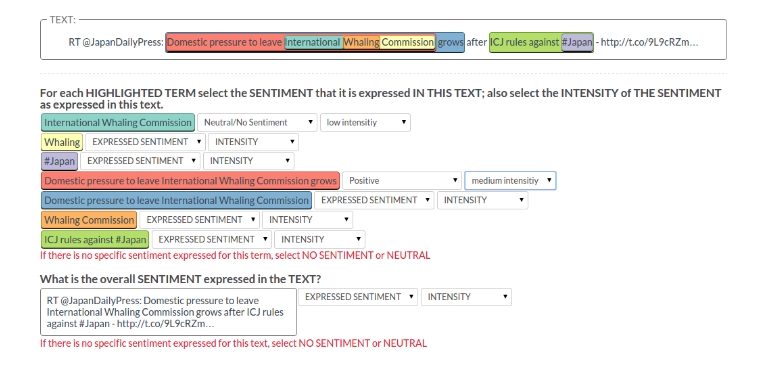
Relevance Analysis" task, for the news articles dataset, the crowd is first asked to select all the relevant snippets with regard to the article title, where the title is considered as an expression of the event and then highlight in them all the relevant event mentions. For the tweets dataset, the crowd is asked to assign relevant events (from a list of predefined events) for each tweet and also highlight all the relevant event mentions in it. This results in a set of relevant snippets and tweets and a set of relevant event mentions in those. Using CrowdTruth cosine similarity metric we compute relevance scores for each snippet, tweet and event mention of the "whaling event".
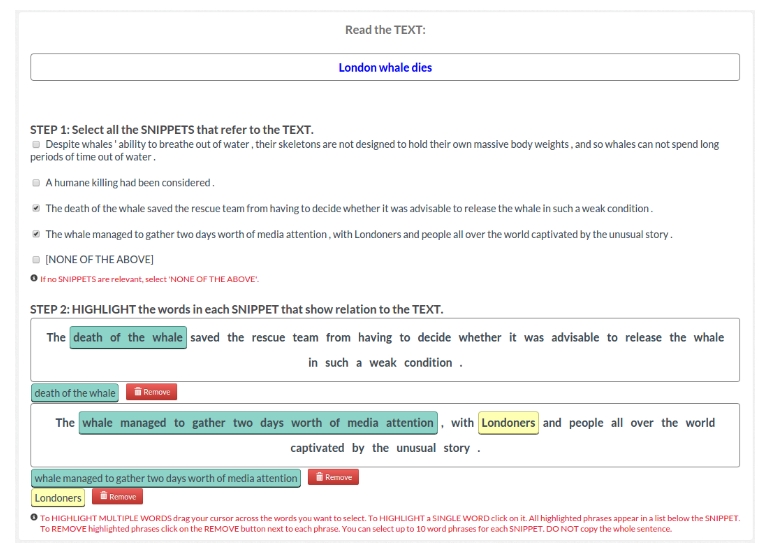
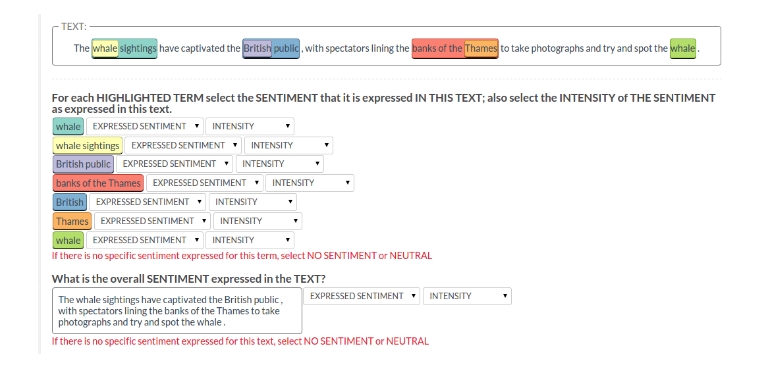
During "
Sentiment Analysis" we gather from the crowd the sentiment (in terms of positive, neutral or negative) and its intensity (high, medium, low) for (1) all event mentions identified in the "
Relevance Analysis" task, and (2) the overall sentiment and its intensity of each snippet and tweet. Here again, we use the CrowdTruth cosine similarity metric to compute sentiment and intensity scores for each event mention, tweet or snippet.
Check the crowdsourcing templates below.
### Relevance Analysis Task on News articles (DS1) (click
here to enlarge the picture and read the crowdsourcing task instructions)
The relevant News Articles to the Whaling Event are used as input for the Sentiment Analysis Task.
### Sentiment Analysis Task on News articles (DS1) (click
here to enlarge the picture and read the crowdsourcing task instructions)
### Relevance Analysis Task on Tweets (DS2&DS3) (click
here to enlarge the picture and read the crowdsourcing task instructions)
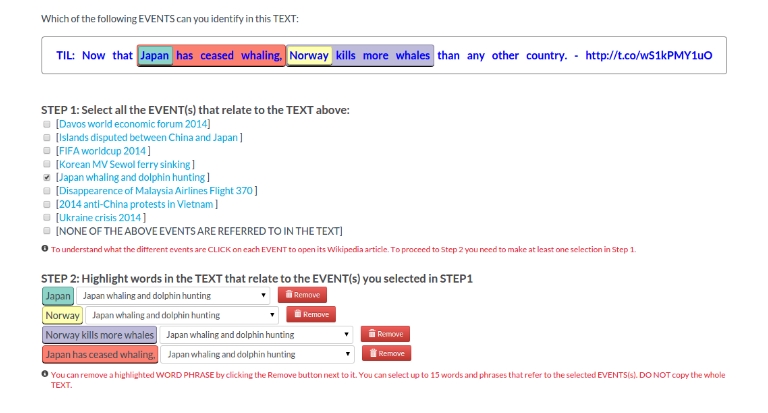
The relevant Tweets to the Whaling Event are used as input for the Sentiment Analysis Task on Tweets
### Sentiment Analysis Task on Tweets (DS2&DS3) (click
here to enlarge the picture and read the crowdsourcing task instructions)